Hi there!
I'm happy to announce version 2.5 of reader, a Python feed reader library.
What's new? #
Here are the most important changes since reader 2.0.
Enable search by default #
Full-text search is now enabled by default – there are no additional dependencies to install, and no required action before using it.
Statistics #
To allow users to understand how they consume content, it is now possible to get some statistics on feed and user activity.
First, you can count the number of entries per day during the last 1, 3, 12 months. This is useful to get an idea of how often a feed / tag / query gets new entries, and how it changes over time.
Second, the time when an entry was last marked as read/important is recorded. This allows seeing if, how often, and how soon you engage with new entries – I'm still working on how to translate this into a useful summary. Also, it allows seeing if an entry was explicitly marked as unimportant.
Improved duplicate handling #
The entry_dedupe plugin got significantly better:
- reduce false negatives by using approximate string matching
- make it possible to re-run the plugin for existing entries
- delete old duplicates instead of marking them as read/unimportant
User-added entries #
Users can now add entries to existing feeds. This is useful when you want to keep track of an article that "fell off the end" of a feed that only has the last X articles.
New data #
You can now get the subtitle and version of a feed. Also, it is possible to know when an entry was added to reader, and by whom (the feed or the user).
New plugin hooks #
It is now possible to run arbitrary actions after a feed is updated.
New Python versions #
reader now supports Python 3.10 and PyPy 3.8.
Other changes #
- A number of convenience properties, methods, and arguments were added.
- The web applications and plugins were updated to take advantage of the features above.
- A number of bugs were fixed and methods were sped up.
See the changelog for details.
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
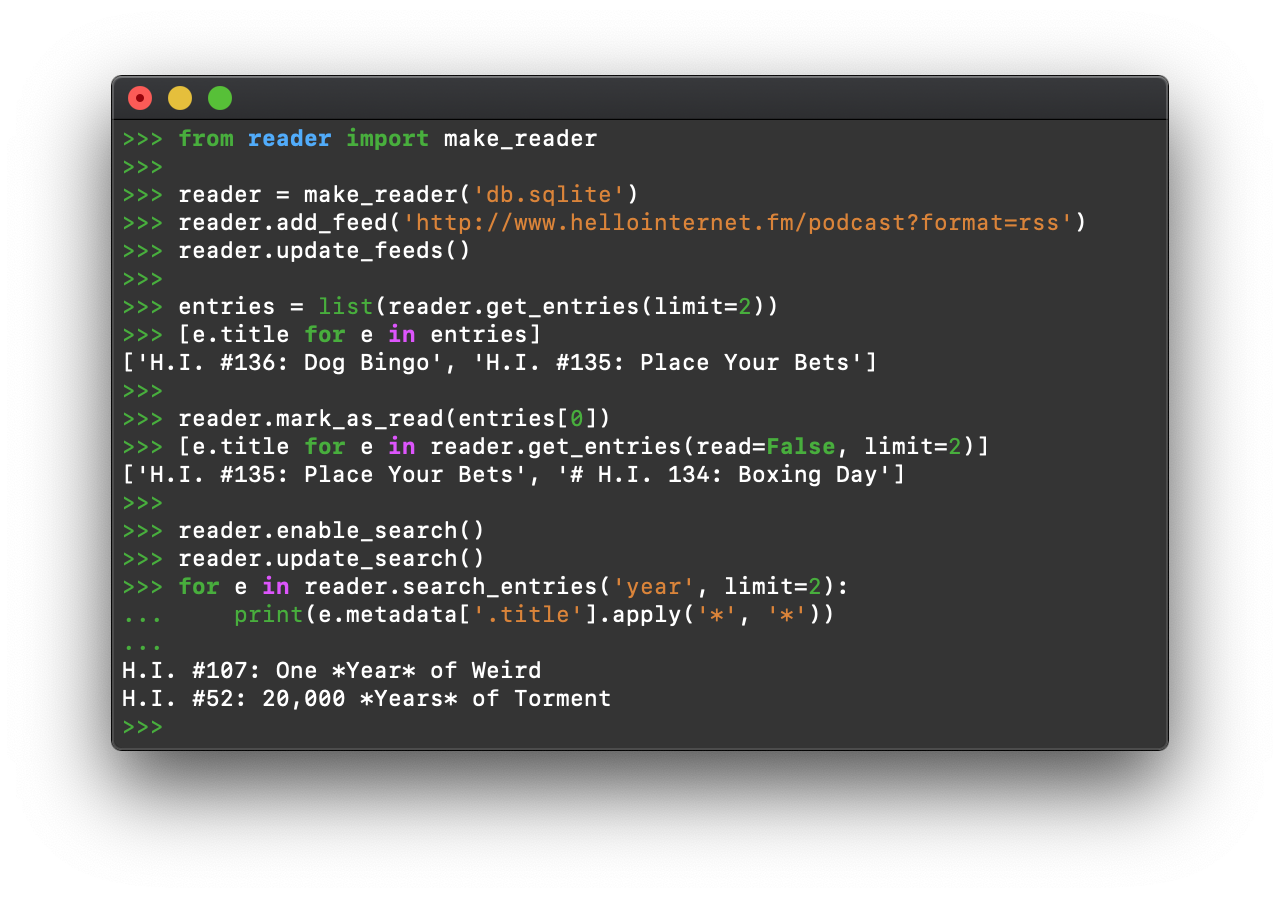 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark entries as read or important
- add tags and metadata to feeds
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.
from Planet Python
via read more



No comments:
Post a Comment