Understanding Autoencoders With Examples
Introduction to Autoencoders
The idea about autoencoders is pretty straight forward. Predict what you input.
-
What is the point then? Well, we know that neural networks (NNs) are just a sequence of matrix multiplications. Let's say the shape of the input matrix is (n, k), which means there are n instances with k features. We want to predict a single output for each of the n instances, that is (n, 1). So we can simply multiply the (n, k) matrix by a (k, 1) matrix to get a (n, 1) matrix. The (n, 1) matrix resulting from this multiplication is then compared with the (n, 1) labels, where the error is used to optimize the (k, 1). But are we really limited to a single (k, 1) matrix? Not at all! We can have much longer sequences, for example:
- Input: (n, k) x (k, 100) x (100, 50) x (50, 20) x (20, 1) ==> (n, 1): Output These intermediary matrices between the input and the output layers are the hidden layers of the neural network. These hidden layers hold latent information about the representation of the input data. For example, if the input is a flattened image. Let's say the image is 800x600 pixels, that's a total of 480,000 pixels. That's a lot of features! But immediately after the first hidden layer (k, 100), that image gets compressed into only 100 dimensions! Why don't we use this magic hidden layer then to reduce the dimensionilty of high-dimensional data, like images or text. Yes, text can be very high dimensional if you want to use one-hot encoding for words in data that has +100k words!
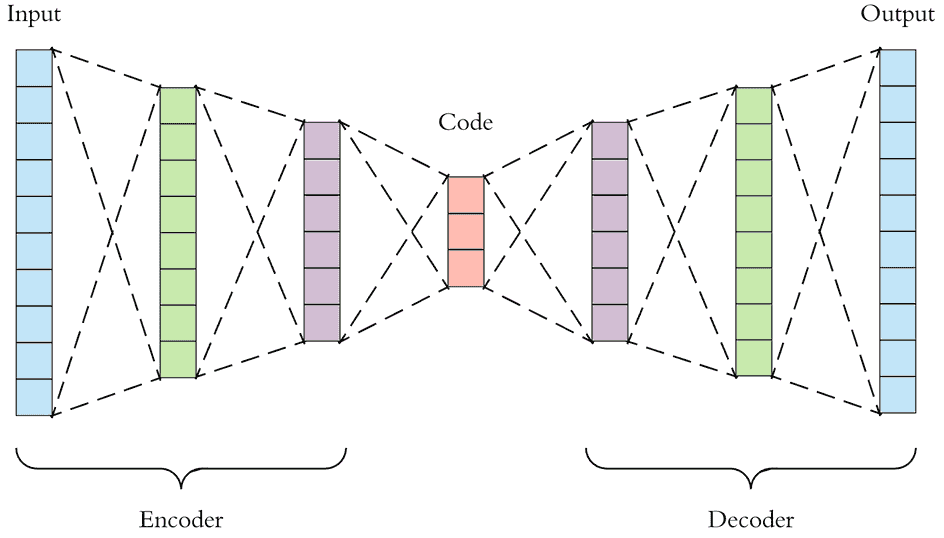
- What can we make out of this then? Give the input to a hidden layer (or layers) and let the output be exactly the same as shape as the input. The goal would be to reproduce the input after multiplying the input with these hidden layers. So basically we compress the input and then decompress it. Or rather, we encode the input then decode it, hence the name autoencoder. Auto because it requires only the input to encode and decode it. And encoder is for the compression/encoding part.
- Where is that useful? This compressed representation of the input has many cool usages:
- Dimensionality Reduction. Your memory will pray for you!
- Image-to-image translation.
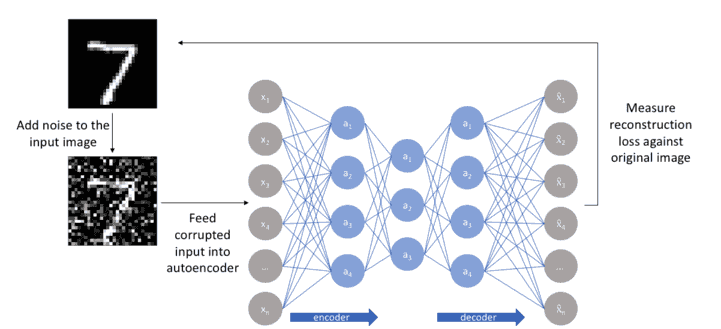
- Denoising.
- Text Representation
Dimensionality Reduction
Autoencoders learn non-linear transformations, making them better than PCA for dimensionality reduction. Check out these results:
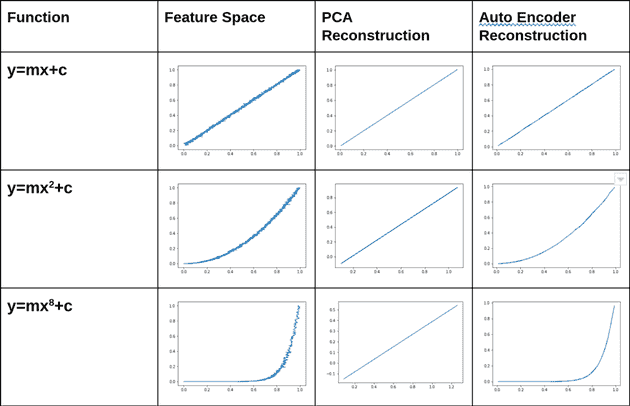
PCA works with linear transformations, so it works with flat surfaces or lines. Autoencoders use activation functions since it is a neural network afterall, so it can model non-linear transformations.
Image-to-image translation
Being compressed, it can be used as an intermediary step (often called a latent space) to transform the input. If you have two images of the same person. One image is with that person wearing glasses, and the other without. If the autoencoder is trained to encode this image, it can be also trained to decode the image with glasses to an image without glasses! Same goes for adding a beard, or making someone blonde. You get the idea. This is called image-to-image transformation, and it requires some tweaking for the network. Here is a slightly different example:

Text-representation
The hidden layer the autoencoder that compresses the input in is actually an embedding! You can call it a latent space, a hidden layer, or an embedding. So, the autoencoder converts the data into an embedding.
Did someone just say embeddings? Yes! we can use autoencoders to learn word embeddings. Let's now do that in Keras.
Check out following links to learn more about word embeddings...
https://www.nbshare.io/notebook/595607887/Understanding-Word-Embeddings-Using-Spacy-Python/
Keras Implementation
The embedding layer
The Embedding layer in keras takes three arguments:
input_dim: The size of the input vectors. In our case, the size of the vocabulary.output_dim: The size of the output vectors. Basically, how many dimensions do you want to compress the data into?\input_length: The length of input sequences. In our cases, the maximum number of words in a sentence.
import numpy as np
docs = [
"Beautifully done!",
"Excellent work",
"Admirable effort",
"Satisfactory performance",
"very bad",
"unacceptable results",
"incompetent with poor skills",
"not cool at all"
]
# let's make this a sentiment analysis task!
labels = np.array([1, 1, 1, 1, 0, 0, 0, 0])
# vocabulary
# by iterating on each document and fetching each word, and converting it to a lower case
# then removing duplicates by converting the resulting list into a set
vocab = set([w.lower() for doc in docs for w in doc.split()])
vocab
vocab_size = len(vocab)
vocab_size
# one-hot encoding
from keras.preprocessing.text import one_hot
encoded_docs = [one_hot(d, vocab_size) for d in docs]
# this will convert sentences into a list of lists with indices of each word in the vocabulary
encoded_docs
# getting the maximum number of words in a sentence in our data
max_length = max([len(doc.split()) for doc in docs])
max_length
from keras.preprocessing.sequence import pad_sequences
# padding sentences with words less than max_length to make all input sequences with the same size
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
padded_docs
from keras.layers import Dense, Flatten
from keras.layers.embeddings import Embedding
from keras.models import Sequential
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=8, input_length=max_length))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid')) # we are using sigmoid here since this is a binary classification task
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
import matplotlib.pyplot as plt
H = model.fit(padded_docs, labels, epochs=50)
fig,ax = plt.subplots(figsize=(16, 9))
ax.plot(H.history["loss"], label="loss", color='r')
ax.set_xlabel("Epoch", fontsize=15)
ax.set_ylabel("Loss", fontsize=15)
ax2 = ax.twinx()
ax2.plot(H.history["accuracy"], label="accuracy", color='b')
ax2.set_ylabel("Accuracy", fontsize=15)
plt.legend()
plt.show()
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print(f'Accuracy: {round(accuracy*100, 2)}')
from sklearn.metrics import classification_report
y_pred = model.predict(padded_docs)>0.5
y_pred
Let us print the confusion matrix
print(classification_report(labels, y_pred))
from Planet Python
via read more



No comments:
Post a Comment