If you’re just starting out in the artificial intelligence (AI) world, then Python is a great language to learn since most of the tools are built using it. Deep learning is a technique used to make predictions using data, and it heavily relies on neural networks. Today, you’ll learn how to build a neural network from scratch.
In a production setting, you would use a deep learning framework like TensorFlow or PyTorch instead of building your own neural network. That said, having some knowledge of how neural networks work is helpful because you can use it to better architect your deep learning models.
In this tutorial, you’ll learn:
- What artificial intelligence is
- How both machine learning and deep learning play a role in AI
- How a neural network functions internally
- How to build a neural network from scratch using Python
Let’s get started!
Free Bonus: Click here to get access to a free NumPy Resources Guide that points you to the best tutorials, videos, and books for improving your NumPy skills.
Artificial Intelligence Overview
In basic terms, the goal of using AI is to make computers think as humans do. This may seem like something new, but the field was born in the 1950s.
Imagine that you need to write a Python program that uses AI to solve a sudoku problem. A way to accomplish that is to write conditional statements and check the constraints to see if you can place a number in each position. Well, this Python script is already an application of AI because you programmed a computer to solve a problem!
Machine learning (ML) and deep learning (DL) are also approaches to solving problems. The difference between these techniques and a Python script is that ML and DL use training data instead of hard-coded rules, but all of them can be used to solve problems using AI. In the next sections, you’ll learn more about what differentiates these two techniques.
Machine Learning
Machine learning is a technique in which you train the system to solve a problem instead of explicitly programming the rules. Getting back to the sudoku example in the previous section, to solve the problem using machine learning, you would gather data from solved sudoku games and train a statistical model. Statistical models are mathematically formalized ways to approximate the behavior of a phenomenon.
A common machine learning task is supervised learning, in which you have a dataset with inputs and known outputs. The task is to use this dataset to train a model that predicts the correct outputs based on the inputs. The image below presents the workflow to train a model using supervised learning:
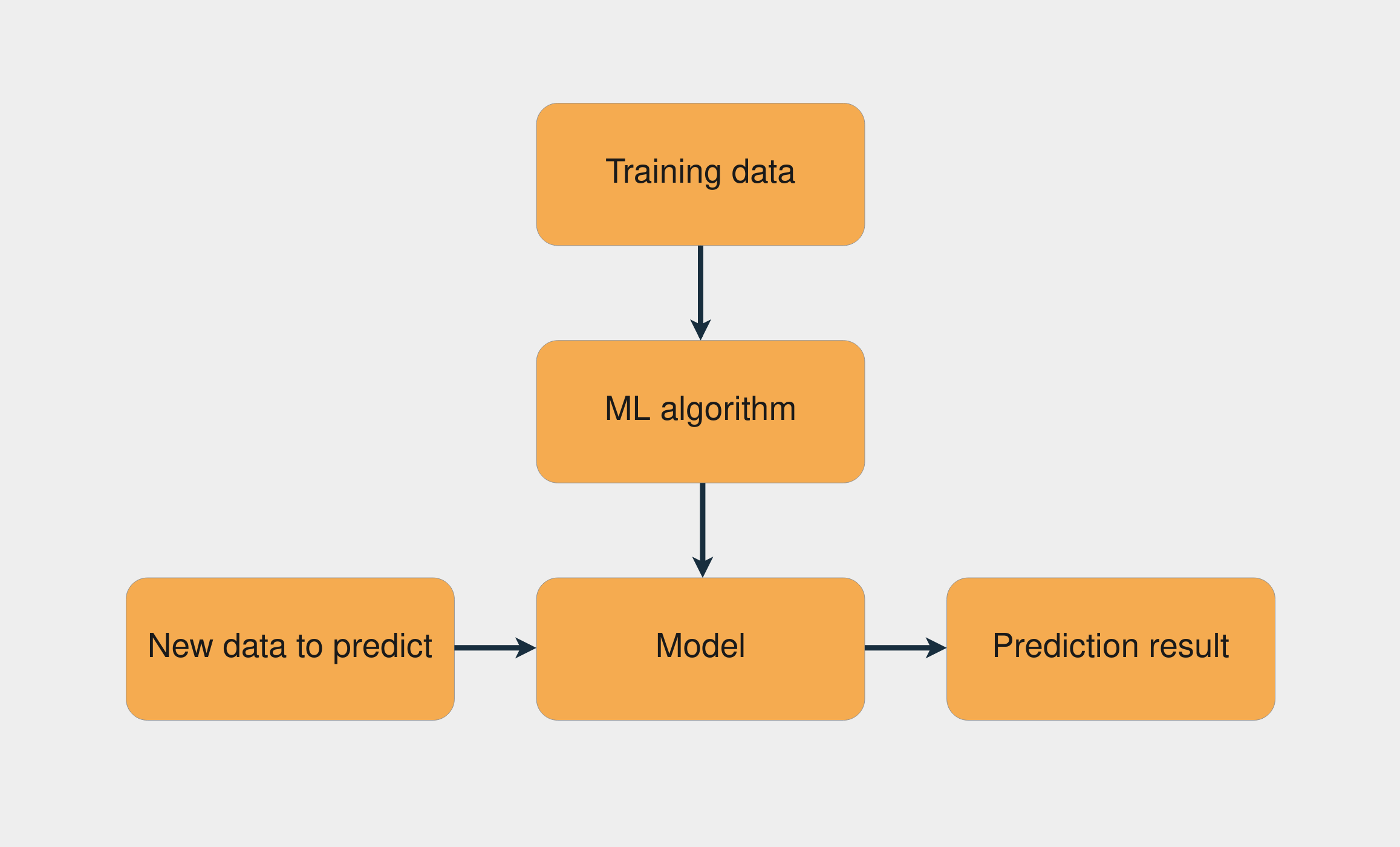
The combination of the training data with the machine learning algorithm creates the model. Then, with this model, you can make predictions for new data.
Note: scikit-learn is a popular Python machine learning library that provides many supervised and unsupervised learning algorithms. To learn more about it, check out Split Your Dataset With scikit-learn’s train_test_split().
The goal of supervised learning tasks is to make predictions for new, unseen data. To do that, you assume that this unseen data follows a probability distribution similar to the distribution of the training dataset. If in the future this distribution changes, then you need to train your model again using the new training dataset.
Feature Engineering
Prediction problems become harder when you use different kinds of data as inputs. The sudoku problem is relatively straightforward because you’re dealing directly with numbers. What if you want to train a model to predict the sentiment in a sentence? Or what if you have an image, and you want to know whether it depicts a cat?
Another name for input data is feature, and feature engineering is the process of extracting features from raw data. When dealing with different kinds of data, you need to figure out ways to represent this data in order to extract meaningful information from it.
An example of a feature engineering technique is lemmatization, in which you remove the inflection from words in a sentence. For example, inflected forms of the verb “watch,” like “watches,” “watching,” and “watched,” would be reduced to their lemma, or base form: “watch.”
If you’re using arrays to store each word of a corpus, then by applying lemmatization, you end up with a less-sparse matrix. This can increase the performance of some machine learning algorithms. The following image presents the process of lemmatization and representation using a bag-of-words model:

First, the inflected form of every word is reduced to its lemma. Then, the number of occurrences of that word is computed. The result is an array containing the number of occurrences of every word in the text.
Deep Learning
Read the full article at https://realpython.com/python-ai-neural-network/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
from Real Python
read more



No comments:
Post a Comment