Pandas’ Series and DataFrame objects are powerful tools for exploring and analyzing data. Part of their power comes from a multifaceted approach to combining separate datasets. With Pandas, you can merge, join, and concatenate your datasets, allowing you to unify and better understand your data as you analyze it.
In this tutorial, you’ll learn how and when to combine your data in Pandas with:
merge()for combining data on common columns or indices.join()for combining data on a key column or an indexconcat()for combining DataFrames across rows or columns
If you have some experience using DataFrame and Series objects in Pandas and you’re ready to learn how to combine them, then this tutorial will help you do exactly that. If you want a quick refresher on DataFrames before proceeding, then Pandas DataFrames 101 will get you caught up in no time.
You can follow along with the examples in this tutorial using the interactive Jupyter Notebook available at the link below:
Get the Jupyter Notebook: Click here to get the Jupyter Notebook you'll use to learn about Pandas merge(), .join(), and concat() in this tutorial.
Note: The techniques you’ll learn about below will generally work for both DataFrame and Series objects. But for simplicity and conciseness, the examples will use the term dataset to refer to objects that can be either DataFrames or Series.
Pandas merge(): Combining Data on Common Columns or Indices
The first technique you’ll learn is merge(). You can use merge() any time you want to do database-like join operations. It’s the most flexible of the three operations you’ll learn.
When you want to combine data objects based on one or more keys in a similar way to a relational database, merge() is the tool you need. More specifically, merge() is most useful when you want to combine rows that share data.
You can achieve both many-to-one and many-to-many joins with merge(). In a many-to-one join, one of your datasets will have many rows in the merge column that repeat the same values (such as 1, 1, 3, 5, 5), while the merge column in the other dataset will not have repeat values (such as 1, 3, 5).
As you might have guessed, in a many-to-many join, both of your merge columns will have repeat values. These merges are more complex and result in the Cartesian product of the joined rows.
This means that, after the merge, you’ll have every combination of rows that share the same value in the key column. You’ll see this in action in the examples below.
What makes merge() so flexible is the sheer number of options for defining the behavior of your merge. While the list can seem daunting, with practice you’ll be able to expertly merge datasets of all kinds.
When you use merge(), you’ll provide two required arguments:
- The
leftDataFrame - The
rightDataFrame
After that, you can provide a number of optional arguments to define how your datasets are merged:
-
how: This defines what kind of merge to make. It defaults to'inner', but other possible options include'outer','left', and'right'. -
on: Use this to tellmerge()which columns or indices (also called key columns or key indices) you want to join on. This is optional. If it isn’t specified, andleft_indexandright_index(covered below) areFalse, then columns from the two DataFrames that share names will be used as join keys. If you useon, then the column or index you specify must be present in both objects. -
left_onandright_on: Use either of these to specify a column or index that is present only in theleftorrightobjects that you are merging. Both default toNone. -
left_indexandright_index: Set these toTrueto use the index of the left or right objects to be merged. Both default toFalse. -
suffixes: This is a tuple of strings to append to identical column names that are not merge keys. This allows you to keep track of the origins of columns with the same name.
These are some of the most important parameters to pass to merge(). For the full list, see the Pandas documentation.
Note: In this tutorial, you’ll see that examples always specify which column(s) to join on with on. This is the safest way to merge your data because you and anyone reading your code will know exactly what to expect when merge() is called. If you do not specify the merge column(s) with on, then Pandas will use any columns with the same name as the merge keys.
How to merge()
Before getting into the details of how to use merge(), you should first understand the various forms of joins:
innerouterleftright
Note: Even though you’re learning about merging, you’ll see inner, outer, left, and right also referred to as join operations. For this tutorial, you can consider these terms equivalent.
You’ll learn about these in detail below, but first take a look at this visual representation of the different joins: 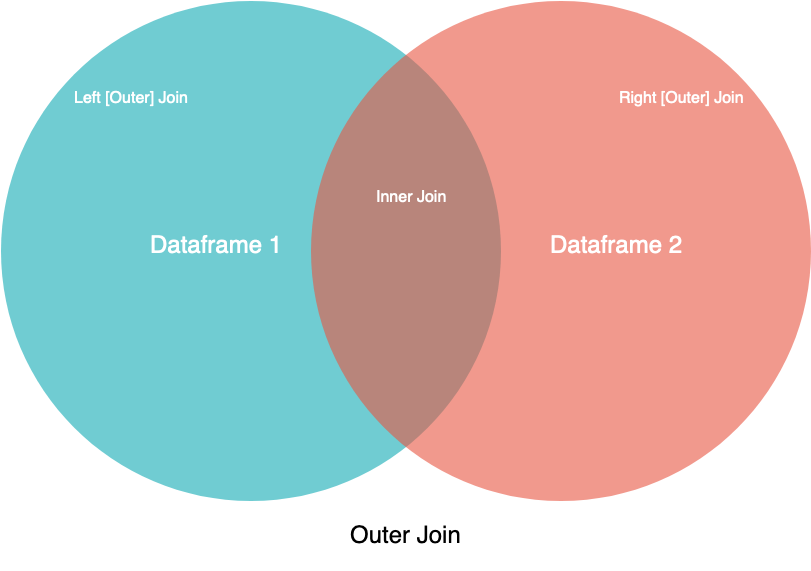 Visual Representation of Join Types
Visual Representation of Join Types
Read the full article at https://realpython.com/pandas-merge-join-and-concat/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
from Planet Python
via read more



No comments:
Post a Comment