spaCy is a free and open-source library for Natural Language Processing (NLP) in Python with a lot of in-built capabilities. It’s becoming increasingly popular for processing and analyzing data in NLP. Unstructured textual data is produced at a large scale, and it’s important to process and derive insights from unstructured data. To do that, you need to represent the data in a format that can be understood by computers. NLP can help you do that.
In this tutorial, you’ll learn:
- What the foundational terms and concepts in NLP are
- How to implement those concepts in spaCy
- How to customize and extend built-in functionalities in spaCy
- How to perform basic statistical analysis on a text
- How to create a pipeline to process unstructured text
- How to parse a sentence and extract meaningful insights from it
Free Bonus: Click here to get access to a chapter from Python Tricks: The Book that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
What Are NLP and spaCy?
NLP is a subfield of Artificial Intelligence and is concerned with interactions between computers and human languages. NLP is the process of analyzing, understanding, and deriving meaning from human languages for computers.
NLP helps you extract insights from unstructured text and has several use cases, such as:
spaCy is a free, open-source library for NLP in Python. It’s written in Cython and is designed to build information extraction or natural language understanding systems. It’s built for production use and provides a concise and user-friendly API.
Installation
In this section, you’ll install spaCy and then download data and models for the English language.
How to Install spaCy
spaCy can be installed using pip, a Python package manager. You can use a virtual environment to avoid depending on system-wide packages. To learn more about virtual environments and pip, check out What Is Pip? A Guide for New Pythonistas and Python Virtual Environments: A Primer.
Create a new virtual environment:
$ python3 -m venv env
Activate this virtual environment and install spaCy:
$ source ./env/bin/activate
$ pip install spacy
How to Download Models and Data
spaCy has different types of models. The default model for the English language is en_core_web_sm.
Activate the virtual environment created in the previous step and download models and data for the English language:
$ python -m spacy download en_core_web_sm
Verify if the download was successful or not by loading it:
>>> import spacy
>>> nlp = spacy.load('en_core_web_sm')
If the nlp object is created, then it means that spaCy was installed and that models and data were successfully downloaded.
Using spaCy
In this section, you’ll use spaCy for a given input string and a text file. Load the language model instance in spaCy:
>>> import spacy
>>> nlp = spacy.load('en_core_web_sm')
Here, the nlp object is a language model instance. You can assume that, throughout this tutorial, nlp refers to the language model loaded by en_core_web_sm. Now you can use spaCy to read a string or a text file.
How to Read a String
You can use spaCy to create a processed Doc object, which is a container for accessing linguistic annotations, for a given input string:
>>> introduction_text = ('This tutorial is about Natural'
... ' Language Processing in Spacy.')
>>> introduction_doc = nlp(introduction_text)
>>> # Extract tokens for the given doc
>>> print ([token.text for token in introduction_doc])
['This', 'tutorial', 'is', 'about', 'Natural', 'Language',
'Processing', 'in', 'Spacy', '.']
In the above example, notice how the text is converted to an object that is understood by spaCy. You can use this method to convert any text into a processed Doc object and deduce attributes, which will be covered in the coming sections.
How to Read a Text File
In this section, you’ll create a processed Doc object for a text file:
>>> file_name = 'introduction.txt'
>>> introduction_file_text = open(file_name).read()
>>> introduction_file_doc = nlp(introduction_file_text)
>>> # Extract tokens for the given doc
>>> print ([token.text for token in introduction_file_doc])
['This', 'tutorial', 'is', 'about', 'Natural', 'Language',
'Processing', 'in', 'Spacy', '.', '\n']
This is how you can convert a text file into a processed Doc object.
Note:
You can assume that:
- Variable names ending with the suffix
_textare Unicode string objects. - Variable name ending with the suffix
_docare spaCy’s language model objects.
Sentence Detection
Sentence Detection is the process of locating the start and end of sentences in a given text. This allows you to you divide a text into linguistically meaningful units. You’ll use these units when you’re processing your text to perform tasks such as part of speech tagging and entity extraction.
In spaCy, the sents property is used to extract sentences. Here’s how you would extract the total number of sentences and the sentences for a given input text:
>>> about_text = ('Gus Proto is a Python developer currently'
... ' working for a London-based Fintech'
... ' company. He is interested in learning'
... ' Natural Language Processing.')
>>> about_doc = nlp(about_text)
>>> sentences = list(about_doc.sents)
>>> len(sentences)
2
>>> for sentence in sentences:
... print (sentence)
...
'Gus Proto is a Python developer currently working for a
London-based Fintech company.'
'He is interested in learning Natural Language Processing.'
In the above example, spaCy is correctly able to identify sentences in the English language, using a full stop(.) as the sentence delimiter. You can also customize the sentence detection to detect sentences on custom delimiters.
Here’s an example, where an ellipsis(...) is used as the delimiter:
>>> def set_custom_boundaries(doc):
... # Adds support to use `...` as the delimiter for sentence detection
... for token in doc[:-1]:
... if token.text == '...':
... doc[token.i+1].is_sent_start = True
... return doc
...
>>> ellipsis_text = ('Gus, can you, ... never mind, I forgot'
... ' what I was saying. So, do you think'
... ' we should ...')
>>> # Load a new model instance
>>> custom_nlp = spacy.load('en_core_web_sm')
>>> custom_nlp.add_pipe(set_custom_boundaries, before='parser')
>>> custom_ellipsis_doc = custom_nlp(ellipsis_text)
>>> custom_ellipsis_sentences = list(custom_ellipsis_doc.sents)
>>> for sentence in custom_ellipsis_sentences:
... print(sentence)
...
Gus, can you, ...
never mind, I forgot what I was saying.
So, do you think we should ...
>>> # Sentence Detection with no customization
>>> ellipsis_doc = nlp(ellipsis_text)
>>> ellipsis_sentences = list(ellipsis_doc.sents)
>>> for sentence in ellipsis_sentences:
... print(sentence)
...
Gus, can you, ... never mind, I forgot what I was saying.
So, do you think we should ...
Note that custom_ellipsis_sentences contain three sentences, whereas ellipsis_sentences contains two sentences. These sentences are still obtained via the sents attribute, as you saw before.
Tokenization in spaCy
Tokenization is the next step after sentence detection. It allows you to identify the basic units in your text. These basic units are called tokens. Tokenization is useful because it breaks a text into meaningful units. These units are used for further analysis, like part of speech tagging.
In spaCy, you can print tokens by iterating on the Doc object:
>>> for token in about_doc:
... print (token, token.idx)
...
Gus 0
Proto 4
is 10
a 13
Python 15
developer 22
currently 32
working 42
for 50
a 54
London 56
- 62
based 63
Fintech 69
company 77
. 84
He 86
is 89
interested 92
in 103
learning 106
Natural 115
Language 123
Processing 132
. 142
Note how spaCy preserves the starting index of the tokens. It’s useful for in-place word replacement. spaCy provides various attributes for the Token class:
>>> for token in about_doc:
... print (token, token.idx, token.text_with_ws,
... token.is_alpha, token.is_punct, token.is_space,
... token.shape_, token.is_stop)
...
Gus 0 Gus True False False Xxx False
Proto 4 Proto True False False Xxxxx False
is 10 is True False False xx True
a 13 a True False False x True
Python 15 Python True False False Xxxxx False
developer 22 developer True False False xxxx False
currently 32 currently True False False xxxx False
working 42 working True False False xxxx False
for 50 for True False False xxx True
a 54 a True False False x True
London 56 London True False False Xxxxx False
- 62 - False True False - False
based 63 based True False False xxxx False
Fintech 69 Fintech True False False Xxxxx False
company 77 company True False False xxxx False
. 84 . False True False . False
He 86 He True False False Xx True
is 89 is True False False xx True
interested 92 interested True False False xxxx False
in 103 in True False False xx True
learning 106 learning True False False xxxx False
Natural 115 Natural True False False Xxxxx False
Language 123 Language True False False Xxxxx False
Processing 132 Processing True False False Xxxxx False
. 142 . False True False . False
In this example, some of the commonly required attributes are accessed:
text_with_wsprints token text with trailing space (if present).is_alphadetects if the token consists of alphabetic characters or not.is_punctdetects if the token is a punctuation symbol or not.is_spacedetects if the token is a space or not.shape_prints out the shape of the word.is_stopdetects if the token is a stop word or not.
Note: You’ll learn more about stop words in the next section.
You can also customize the tokenization process to detect tokens on custom characters. This is often used for hyphenated words, which are words joined with hyphen. For example, “London-based” is a hyphenated word.
spaCy allows you to customize tokenization by updating the tokenizer property on the nlp object:
>>> import re
>>> import spacy
>>> from spacy.tokenizer import Tokenizer
>>> custom_nlp = spacy.load('en_core_web_sm')
>>> prefix_re = spacy.util.compile_prefix_regex(custom_nlp.Defaults.prefixes)
>>> suffix_re = spacy.util.compile_suffix_regex(custom_nlp.Defaults.suffixes)
>>> infix_re = re.compile(r'''[-~]''')
>>> def customize_tokenizer(nlp):
... # Adds support to use `-` as the delimiter for tokenization
... return Tokenizer(nlp.vocab, prefix_search=prefix_re.search,
... suffix_search=suffix_re.search,
... infix_finditer=infix_re.finditer,
... token_match=None
... )
...
>>> custom_nlp.tokenizer = customize_tokenizer(custom_nlp)
>>> custom_tokenizer_about_doc = custom_nlp(about_text)
>>> print([token.text for token in custom_tokenizer_about_doc])
['Gus', 'Proto', 'is', 'a', 'Python', 'developer', 'currently',
'working', 'for', 'a', 'London', '-', 'based', 'Fintech',
'company', '.', 'He', 'is', 'interested', 'in', 'learning',
'Natural', 'Language', 'Processing', '.']
In order for you to customize, you can pass various parameters to the Tokenizer class:
nlp.vocabis a storage container for special cases and is used to handle cases like contractions and emoticons.prefix_searchis the function that is used to handle preceding punctuation, such as opening parentheses.infix_finditeris the function that is used to handle non-whitespace separators, such as hyphens.suffix_searchis the function that is used to handle succeeding punctuation, such as closing parentheses.token_matchis an optional boolean function that is used to match strings that should never be split. It overrides the previous rules and is useful for entities like URLs or numbers.
Note: spaCy already detects hyphenated words as individual tokens. The above code is just an example to show how tokenization can be customized. It can be used for any other character.
Stop Words
Stop words are the most common words in a language. In the English language, some examples of stop words are the, are, but, and they. Most sentences need to contain stop words in order to be full sentences that make sense.
Generally, stop words are removed because they aren’t significant and distort the word frequency analysis. spaCy has a list of stop words for the English language:
>>> import spacy
>>> spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS
>>> len(spacy_stopwords)
326
>>> for stop_word in list(spacy_stopwords)[:10]:
... print(stop_word)
...
using
becomes
had
itself
once
often
is
herein
who
too
You can remove stop words from the input text:
>>> for token in about_doc:
... if not token.is_stop:
... print (token)
...
Gus
Proto
Python
developer
currently
working
London
-
based
Fintech
company
.
interested
learning
Natural
Language
Processing
.
Stop words like is, a, for, the, and in are not printed in the output above. You can also create a list of tokens not containing stop words:
>>> about_no_stopword_doc = [token for token in about_doc if not token.is_stop]
>>> print (about_no_stopword_doc)
[Gus, Proto, Python, developer, currently, working, London,
-, based, Fintech, company, ., interested, learning, Natural,
Language, Processing, .]
about_no_stopword_doc can be joined with spaces to form a sentence with no stop words.
Lemmatization
Lemmatization is the process of reducing inflected forms of a word while still ensuring that the reduced form belongs to the language. This reduced form or root word is called a lemma.
For example, organizes, organized and organizing are all forms of organize. Here, organize is the lemma. The inflection of a word allows you to express different grammatical categories like tense (organized vs organize), number (trains vs train), and so on. Lemmatization is necessary because it helps you reduce the inflected forms of a word so that they can be analyzed as a single item. It can also help you normalize the text.
spaCy has the attribute lemma_ on the Token class. This attribute has the lemmatized form of a token:
>>> conference_help_text = ('Gus is helping organize a developer'
... 'conference on Applications of Natural Language'
... ' Processing. He keeps organizing local Python meetups'
... ' and several internal talks at his workplace.')
>>> conference_help_doc = nlp(conference_help_text)
>>> for token in conference_help_doc:
... print (token, token.lemma_)
...
Gus Gus
is be
helping help
organize organize
a a
developer developer
conference conference
on on
Applications Applications
of of
Natural Natural
Language Language
Processing Processing
. .
He -PRON-
keeps keep
organizing organize
local local
Python Python
meetups meetup
and and
several several
internal internal
talks talk
at at
his -PRON-
workplace workplace
. .
In this example, organizing reduces to its lemma form organize. If you do not lemmatize the text, then organize and organizing will be counted as different tokens, even though they both have a similar meaning. Lemmatization helps you avoid duplicate words that have similar meanings.
Word Frequency
You can now convert a given text into tokens and perform statistical analysis over it. This analysis can give you various insights about word patterns, such as common words or unique words in the text:
>>> from collections import Counter
>>> complete_text = ('Gus Proto is a Python developer currently'
... 'working for a London-based Fintech company. He is'
... ' interested in learning Natural Language Processing.'
... ' There is a developer conference happening on 21 July'
... ' 2019 in London. It is titled "Applications of Natural'
... ' Language Processing". There is a helpline number '
... ' available at +1-1234567891. Gus is helping organize it.'
... ' He keeps organizing local Python meetups and several'
... ' internal talks at his workplace. Gus is also presenting'
... ' a talk. The talk will introduce the reader about "Use'
... ' cases of Natural Language Processing in Fintech".'
... ' Apart from his work, he is very passionate about music.'
... ' Gus is learning to play the Piano. He has enrolled '
... ' himself in the weekend batch of Great Piano Academy.'
... ' Great Piano Academy is situated in Mayfair or the City'
... ' of London and has world-class piano instructors.')
...
>>> complete_doc = nlp(complete_text)
>>> # Remove stop words and punctuation symbols
>>> words = [token.text for token in complete_doc
... if not token.is_stop and not token.is_punct]
>>> word_freq = Counter(words)
>>> # 5 commonly occurring words with their frequencies
>>> common_words = word_freq.most_common(5)
>>> print (common_words)
[('Gus', 4), ('London', 3), ('Natural', 3), ('Language', 3), ('Processing', 3)]
>>> # Unique words
>>> unique_words = [word for (word, freq) in word_freq.items() if freq == 1]
>>> print (unique_words)
['Proto', 'currently', 'working', 'based', 'company',
'interested', 'conference', 'happening', '21', 'July',
'2019', 'titled', 'Applications', 'helpline', 'number',
'available', '+1', '1234567891', 'helping', 'organize',
'keeps', 'organizing', 'local', 'meetups', 'internal',
'talks', 'workplace', 'presenting', 'introduce', 'reader',
'Use', 'cases', 'Apart', 'work', 'passionate', 'music', 'play',
'enrolled', 'weekend', 'batch', 'situated', 'Mayfair', 'City',
'world', 'class', 'piano', 'instructors']
By looking at the common words, you can see that the text as a whole is probably about Gus, London, or Natural Language Processing. This way, you can take any unstructured text and perform statistical analysis to know what it’s about.
Here’s another example of the same text with stop words:
>>> words_all = [token.text for token in complete_doc if not token.is_punct]
>>> word_freq_all = Counter(words_all)
>>> # 5 commonly occurring words with their frequencies
>>> common_words_all = word_freq_all.most_common(5)
>>> print (common_words_all)
[('is', 10), ('a', 5), ('in', 5), ('Gus', 4), ('of', 4)]
Four out of five of the most common words are stop words, which don’t tell you much about the text. If you consider stop words while doing word frequency analysis, then you won’t be able to derive meaningful insights from the input text. This is why removing stop words is so important.
Part of Speech Tagging
Part of speech or POS is a grammatical role that explains how a particular word is used in a sentence. There are eight parts of speech:
- Noun
- Pronoun
- Adjective
- Verb
- Adverb
- Preposition
- Conjunction
- Interjection
Part of speech tagging is the process of assigning a POS tag to each token depending on its usage in the sentence. POS tags are useful for assigning a syntactic category like noun or verb to each word.
In spaCy, POS tags are available as an attribute on the Token object:
>>> for token in about_doc:
... print (token, token.tag_, token.pos_, spacy.explain(token.tag_))
...
Gus NNP PROPN noun, proper singular
Proto NNP PROPN noun, proper singular
is VBZ VERB verb, 3rd person singular present
a DT DET determiner
Python NNP PROPN noun, proper singular
developer NN NOUN noun, singular or mass
currently RB ADV adverb
working VBG VERB verb, gerund or present participle
for IN ADP conjunction, subordinating or preposition
a DT DET determiner
London NNP PROPN noun, proper singular
- HYPH PUNCT punctuation mark, hyphen
based VBN VERB verb, past participle
Fintech NNP PROPN noun, proper singular
company NN NOUN noun, singular or mass
. . PUNCT punctuation mark, sentence closer
He PRP PRON pronoun, personal
is VBZ VERB verb, 3rd person singular present
interested JJ ADJ adjective
in IN ADP conjunction, subordinating or preposition
learning VBG VERB verb, gerund or present participle
Natural NNP PROPN noun, proper singular
Language NNP PROPN noun, proper singular
Processing NNP PROPN noun, proper singular
. . PUNCT punctuation mark, sentence closer
Here, two attributes of the Token class are accessed:
tag_lists the fine-grained part of speech.pos_lists the coarse-grained part of speech.
spacy.explain gives descriptive details about a particular POS tag. spaCy provides a complete tag list along with an explanation for each tag.
Using POS tags, you can extract a particular category of words:
>>> nouns = []
>>> adjectives = []
>>> for token in about_doc:
... if token.pos_ == 'NOUN':
... nouns.append(token)
... if token.pos_ == 'ADJ':
... adjectives.append(token)
...
>>> nouns
[developer, company]
>>> adjectives
[interested]
You can use this to derive insights, remove the most common nouns, or see which adjectives are used for a particular noun.
Visualization: Using displaCy
spaCy comes with a built-in visualizer called displaCy. You can use it to visualize a dependency parse or named entities in a browser or a Jupyter notebook.
You can use displaCy to find POS tags for tokens:
>>> from spacy import displacy
>>> about_interest_text = ('He is interested in learning'
... ' Natural Language Processing.')
>>> about_interest_doc = nlp(about_interest_text)
>>> displacy.serve(about_interest_doc, style='dep')
The above code will spin a simple web server. You can see the visualization by opening http://127.0.0.1:5000 in your browser:
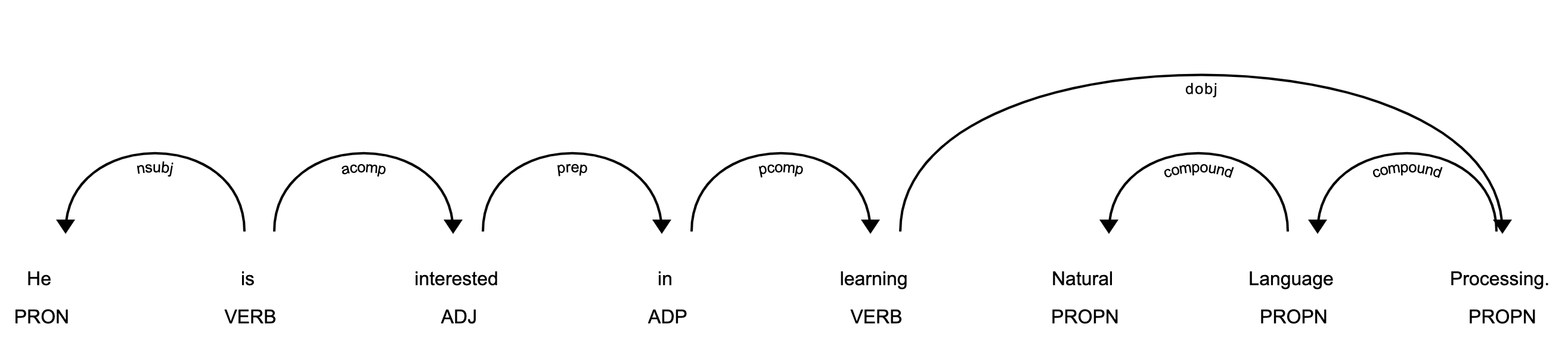 displaCy: Part of Speech Tagging Demo
displaCy: Part of Speech Tagging Demo
In the image above, each token is assigned a POS tag written just below the token.
Note: Here’s how you can use displaCy in a Jupyter notebook:
>>> displacy.render(about_interest_doc, style='dep', jupyter=True)
Preprocessing Functions
You can create a preprocessing function that takes text as input and applies the following operations:
- Lowercases the text
- Lemmatizes each token
- Removes punctuation symbols
- Removes stop words
A preprocessing function converts text to an analyzable format. It’s necessary for most NLP tasks. Here’s an example:
>>> def is_token_allowed(token):
... '''
... Only allow valid tokens which are not stop words
... and punctuation symbols.
... '''
... if (not token or not token.string.strip() or
... token.is_stop or token.is_punct):
... return False
... return True
...
>>> def preprocess_token(token):
... # Reduce token to its lowercase lemma form
... return token.lemma_.strip().lower()
...
>>> complete_filtered_tokens = [preprocess_token(token)
... for token in complete_doc if is_token_allowed(token)]
>>> complete_filtered_tokens
['gus', 'proto', 'python', 'developer', 'currently', 'work',
'london', 'base', 'fintech', 'company', 'interested', 'learn',
'natural', 'language', 'processing', 'developer', 'conference',
'happen', '21', 'july', '2019', 'london', 'title',
'applications', 'natural', 'language', 'processing', 'helpline',
'number', 'available', '+1', '1234567891', 'gus', 'help',
'organize', 'keep', 'organize', 'local', 'python', 'meetup',
'internal', 'talk', 'workplace', 'gus', 'present', 'talk', 'talk',
'introduce', 'reader', 'use', 'case', 'natural', 'language',
'processing', 'fintech', 'apart', 'work', 'passionate', 'music',
'gus', 'learn', 'play', 'piano', 'enrol', 'weekend', 'batch',
'great', 'piano', 'academy', 'great', 'piano', 'academy',
'situate', 'mayfair', 'city', 'london', 'world', 'class',
'piano', 'instructor']
Note that the complete_filtered_tokens does not contain any stop word or punctuation symbols and consists of lemmatized lowercase tokens.
Rule-Based Matching Using spaCy
Rule-based matching is one of the steps in extracting information from unstructured text. It’s used to identify and extract tokens and phrases according to patterns (such as lowercase) and grammatical features (such as part of speech).
Rule-based matching can use regular expressions to extract entities (such as phone numbers) from an unstructured text. It’s different from extracting text using regular expressions only in the sense that regular expressions don’t consider the lexical and grammatical attributes of the text.
With rule-based matching, you can extract a first name and a last name, which are always proper nouns:
>>> from spacy.matcher import Matcher
>>> matcher = Matcher(nlp.vocab)
>>> def extract_full_name(nlp_doc):
... pattern = [{'POS': 'PROPN'}, {'POS': 'PROPN'}]
... matcher.add('FULL_NAME', None, pattern)
... matches = matcher(nlp_doc)
... for match_id, start, end in matches:
... span = nlp_doc[start:end]
... return span.text
...
>>> extract_full_name(about_doc)
'Gus Proto'
In this example, pattern is a list of objects that defines the combination of tokens to be matched. Both POS tags in it are PROPN (proper noun). So, the pattern consists of two objects in which the POS tags for both tokens should be PROPN. This pattern is then added to Matcher using FULL_NAME and the the match_id. Finally, matches are obtained with their starting and end indexes.
You can also use rule-based matching to extract phone numbers:
>>> from spacy.matcher import Matcher
>>> matcher = Matcher(nlp.vocab)
>>> conference_org_text = ('There is a developer conference'
... 'happening on 21 July 2019 in London. It is titled'
... ' "Applications of Natural Language Processing".'
... ' There is a helpline number available'
... ' at (123) 456-789')
...
>>> def extract_phone_number(nlp_doc):
... pattern = [{'ORTH': '('}, {'SHAPE': 'ddd'},
... {'ORTH': ')'}, {'SHAPE': 'ddd'},
... {'ORTH': '-', 'OP': '?'},
... {'SHAPE': 'ddd'}]
... matcher.add('PHONE_NUMBER', None, pattern)
... matches = matcher(nlp_doc)
... for match_id, start, end in matches:
... span = nlp_doc[start:end]
... return span.text
...
>>> conference_org_doc = nlp(conference_org_text)
>>> extract_phone_number(conference_org_doc)
'(123) 456-789'
In this example, only the pattern is updated in order to match phone numbers from the previous example. Here, some attributes of the token are also used:
ORTHgives the exact text of the token.SHAPEtransforms the token string to show orthographic features.OPdefines operators. Using?as a value means that the pattern is optional, meaning it can match 0 or 1 times.
Note: For simplicity, phone numbers are assumed to be of a particular format: (123) 456-789. You can change this depending on your use case.
Rule-based matching helps you identify and extract tokens and phrases according to lexical patterns (such as lowercase) and grammatical features(such as part of speech).
Dependency Parsing Using spaCy
Dependency parsing is the process of extracting the dependency parse of a sentence to represent its grammatical structure. It defines the dependency relationship between headwords and their dependents. The head of a sentence has no dependency and is called the root of the sentence. The verb is usually the head of the sentence. All other words are linked to the headword.
The dependencies can be mapped in a directed graph representation:
- Words are the nodes.
- The grammatical relationships are the edges.
Dependency parsing helps you know what role a word plays in the text and how different words relate to each other. It’s also used in shallow parsing and named entity recognition.
Here’s how you can use dependency parsing to see the relationships between words:
>>> piano_text = 'Gus is learning piano'
>>> piano_doc = nlp(piano_text)
>>> for token in piano_doc:
... print (token.text, token.tag_, token.head.text, token.dep_)
...
Gus NNP learning nsubj
is VBZ learning aux
learning VBG learning ROOT
piano NN learning dobj
In this example, the sentence contains three relationships:
nsubjis the subject of the word. Its headword is a verb.auxis an auxiliary word. Its headword is a verb.dobjis the direct object of the verb. Its headword is a verb.
There is a detailed list of relationships with descriptions. You can use displaCy to visualize the dependency tree:
>>> displacy.serve(piano_doc, style='dep')
This code will produce a visualization that can be accessed by opening http://127.0.0.1:5000 in your browser:
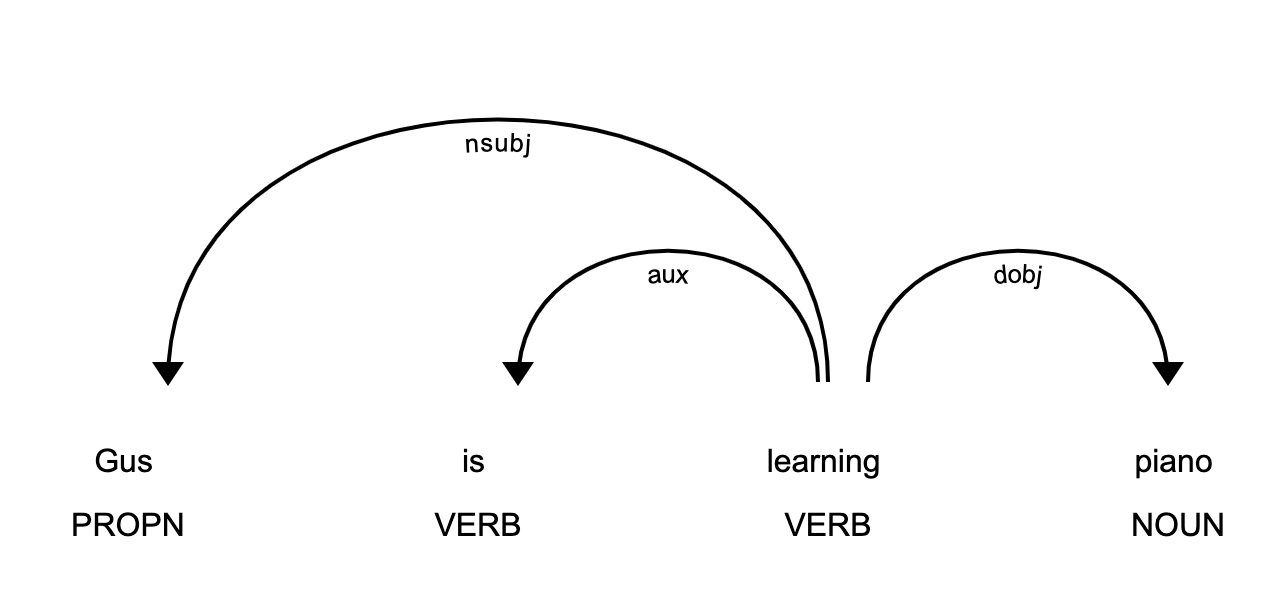 displaCy: Dependency Parse Demo
displaCy: Dependency Parse Demo
This image shows you that the subject of the sentence is the proper noun Gus and that it has a learn relationship with piano.
Navigating the Tree and Subtree
The dependency parse tree has all the properties of a tree. This tree contains information about sentence structure and grammar and can be traversed in different ways to extract relationships.
spaCy provides attributes like children, lefts, rights, and subtree to navigate the parse tree:
>>> one_line_about_text = ('Gus Proto is a Python developer'
... ' currently working for a London-based Fintech company')
>>> one_line_about_doc = nlp(one_line_about_text)
>>> # Extract children of `developer`
>>> print([token.text for token in one_line_about_doc[5].children])
['a', 'Python', 'working']
>>> # Extract previous neighboring node of `developer`
>>> print (one_line_about_doc[5].nbor(-1))
Python
>>> # Extract next neighboring node of `developer`
>>> print (one_line_about_doc[5].nbor())
currently
>>> # Extract all tokens on the left of `developer`
>>> print([token.text for token in one_line_about_doc[5].lefts])
['a', 'Python']
>>> # Extract tokens on the right of `developer`
>>> print([token.text for token in one_line_about_doc[5].rights])
['working']
>>> # Print subtree of `developer`
>>> print (list(one_line_about_doc[5].subtree))
[a, Python, developer, currently, working, for, a, London, -,
based, Fintech, company]
You can construct a function that takes a subtree as an argument and returns a string by merging words in it:
>>> def flatten_tree(tree):
... return ''.join([token.text_with_ws for token in list(tree)]).strip()
...
>>> # Print flattened subtree of `developer`
>>> print (flatten_tree(one_line_about_doc[5].subtree))
a Python developer currently working for a London-based Fintech company
You can use this function to print all the tokens in a subtree.
Shallow Parsing
Shallow parsing, or chunking, is the process of extracting phrases from unstructured text. Chunking groups adjacent tokens into phrases on the basis of their POS tags. There are some standard well-known chunks such as noun phrases, verb phrases, and prepositional phrases.
Noun Phrase Detection
A noun phrase is a phrase that has a noun as its head. It could also include other kinds of words, such as adjectives, ordinals, determiners. Noun phrases are useful for explaining the context of the sentence. They help you infer what is being talked about in the sentence.
spaCy has the property noun_chunks on Doc object. You can use it to extract noun phrases:
>>> conference_text = ('There is a developer conference'
... ' happening on 21 July 2019 in London.')
>>> conference_doc = nlp(conference_text)
>>> # Extract Noun Phrases
>>> for chunk in conference_doc.noun_chunks:
... print (chunk)
...
a developer conference
21 July
London
By looking at noun phrases, you can get information about your text. For example, a developer conference indicates that the text mentions a conference, while the date 21 July lets you know that conference is scheduled for 21 July. You can figure out whether the conference is in the past or the future. London tells you that the conference is in London.
Verb Phrase Detection
A verb phrase is a syntactic unit composed of at least one verb. This verb can be followed by other chunks, such as noun phrases. Verb phrases are useful for understanding the actions that nouns are involved in.
spaCy has no built-in functionality to extract verb phrases, so you’ll need a library called textacy:
Note:
You can use pip to install textacy:
$ pip install textacy
Now that you have textacy installed, you can use it to extract verb phrases based on grammar rules:
>>> import textacy
>>> about_talk_text = ('The talk will introduce reader about Use'
... ' cases of Natural Language Processing in'
... ' Fintech')
>>> pattern = r'(<VERB>?<ADV>*<VERB>+)'
>>> about_talk_doc = textacy.make_spacy_doc(about_talk_text,
... lang='en_core_web_sm')
>>> verb_phrases = textacy.extract.pos_regex_matches(about_talk_doc, pattern)
>>> # Print all Verb Phrase
>>> for chunk in verb_phrases:
... print(chunk.text)
...
will introduce
>>> # Extract Noun Phrase to explain what nouns are involved
>>> for chunk in about_talk_doc.noun_chunks:
... print (chunk)
...
The talk
reader
Use cases
Natural Language Processing
Fintech
In this example, the verb phrase introduce indicates that something will be introduced. By looking at noun phrases, you can see that there is a talk that will introduce the reader to use cases of Natural Language Processing or Fintech.
The above code extracts all the verb phrases using a regular expression pattern of POS tags. You can tweak the pattern for verb phrases depending upon your use case.
Note: In the previous example, you could have also done dependency parsing to see what the relationships between the words were.
Named Entity Recognition
Named Entity Recognition (NER) is the process of locating named entities in unstructured text and then classifying them into pre-defined categories, such as person names, organizations, locations, monetary values, percentages, time expressions, and so on.
You can use NER to know more about the meaning of your text. For example, you could use it to populate tags for a set of documents in order to improve the keyword search. You could also use it to categorize customer support tickets into relevant categories.
spaCy has the property ents on Doc objects. You can use it to extract named entities:
>>> piano_class_text = ('Great Piano Academy is situated'
... ' in Mayfair or the City of London and has'
... ' world-class piano instructors.')
>>> piano_class_doc = nlp(piano_class_text)
>>> for ent in piano_class_doc.ents:
... print(ent.text, ent.start_char, ent.end_char,
... ent.label_, spacy.explain(ent.label_))
...
Great Piano Academy 0 19 ORG Companies, agencies, institutions, etc.
Mayfair 35 42 GPE Countries, cities, states
the City of London 46 64 GPE Countries, cities, states
In the above example, ent is a Span object with various attributes:
textgives the Unicode text representation of the entity.start_chardenotes the character offset for the start of the entity.end_chardenotes the character offset for the end of the entity.label_gives the label of the entity.
spacy.explain gives descriptive details about an entity label. The spaCy model has a pre-trained list of entity classes. You can use displaCy to visualize these entities:
>>> displacy.serve(piano_class_doc, style='ent')
If you open http://127.0.0.1:5000 in your browser, then you can see the visualization:
 displaCy: Named Entity Recognition Demo
displaCy: Named Entity Recognition Demo
You can use NER to redact people’s names from a text. For example, you might want to do this in order to hide personal information collected in a survey. You can use spaCy to do that:
>>> survey_text = ('Out of 5 people surveyed, James Robert,'
... ' Julie Fuller and Benjamin Brooks like'
... ' apples. Kelly Cox and Matthew Evans'
... ' like oranges.')
...
>>> def replace_person_names(token):
... if token.ent_iob != 0 and token.ent_type_ == 'PERSON':
... return '[REDACTED] '
... return token.string
...
>>> def redact_names(nlp_doc):
... for ent in nlp_doc.ents:
... ent.merge()
... tokens = map(replace_person_names, nlp_doc)
... return ''.join(tokens)
...
>>> survey_doc = nlp(survey_text)
>>> redact_names(survey_doc)
'Out of 5 people surveyed, [REDACTED] , [REDACTED] and'
' [REDACTED] like apples. [REDACTED] and [REDACTED]'
' like oranges.'
In this example, replace_person_names() uses ent_iob. It gives the IOB code of the named entity tag using inside-outside-beginning (IOB) tagging. Here, it can assume a value other than zero, because zero means that no entity tag is set.
Conclusion
spaCy is a powerful and advanced library that is gaining huge popularity for NLP applications due to its speed, ease of use, accuracy, and extensibility. Congratulations! You now know:
- What the foundational terms and concepts in NLP are
- How to implement those concepts in spaCy
- How to customize and extend built-in functionalities in spaCy
- How to perform basic statistical analysis on a text
- How to create a pipeline to process unstructured text
- How to parse a sentence and extract meaningful insights from it
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
from Planet Python
via read more



No comments:
Post a Comment