This an optimization story that should not surprise anyone using the Django ORM. But I thought I'd share because I have numbers now! The origin of this came from a real requirement. For a given parent model, I'd like to extract the value of the name column of all its child models, and the turn all these name strings into 1 MD5 checksum string.
Variants
The first attempted looked like this:
artist = Artist.objects.get(name="Bad Religion")
names = []
for song in Song.objects.filter(artist=artist):
names.append(song.name)
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
The SQL used to generate this is as follows:
SELECT "main_song"."id", "main_song"."artist_id", "main_song"."name",
"main_song"."text", "main_song"."language", "main_song"."key_phrases",
"main_song"."popularity", "main_song"."text_length", "main_song"."metadata",
"main_song"."created", "main_song"."modified",
"main_song"."has_lastfm_listeners", "main_song"."has_spotify_popularity"
FROM "main_song" WHERE "main_song"."artist_id" = 22729;
Clearly, I don't need anything but just the name column, version 2:
artist = Artist.objects.get(name="Bad Religion")
names = []
for song in Song.objects.filter(artist=artist).only("name"):
names.append(song.name)
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
Now, the SQL used is:
SELECT "main_song"."id", "main_song"."name"
FROM "main_song" WHERE "main_song"."artist_id" = 22729;
But still, since I don't really need instances of model class Song I can use the .values() method which gives back a list of dictionaries. This is version 3:
names = []
for song in Song.objects.filter(artist=a).values("name"):
names.append(song["name"])
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
This time Django figures it doesn't even need the primary key value so it looks like this:
SELECT "main_song"."name" FROM "main_song" WHERE "main_song"."artist_id" = 22729;
Last but not least; there is an even faster one. values_list(). This time it doesn't even bother to map the column name to the value in a dictionary. And since I only need 1 column's value, I can set flat=True. Version 4 looks like this:
names = []
for name in Song.objects.filter(artist=a).values_list("name", flat=True):
names.append(name)
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
Same SQL gets used this time as in version 3.
The benchmark
Hopefully this little benchmark script speaks for itself:
from songsearch.main.models import *
import hashlib
def f1(a):
names = []
for song in Song.objects.filter(artist=a):
names.append(song.name)
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
def f2(a):
names = []
for song in Song.objects.filter(artist=a).only("name"):
names.append(song.name)
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
def f3(a):
names = []
for song in Song.objects.filter(artist=a).values("name"):
names.append(song["name"])
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
def f4(a):
names = []
for name in Song.objects.filter(artist=a).values_list("name", flat=True):
names.append(name)
return hashlib.md5("".join(names).encode("utf-8")).hexdigest()
artist = Artist.objects.get(name="Bad Religion")
print(Song.objects.filter(artist=artist).count())
print(f1(artist) == f2(artist))
print(f2(artist) == f3(artist))
print(f3(artist) == f4(artist))
# Reporting
import time
import random
import statistics
functions = f1, f2, f3, f4
times = {f.__name__: [] for f in functions}
for i in range(500):
func = random.choice(functions)
t0 = time.time()
func(artist)
t1 = time.time()
times[func.__name__].append((t1 - t0) * 1000)
for name in sorted(times):
numbers = times[name]
print("FUNCTION:", name, "Used", len(numbers), "times")
print("\tBEST", min(numbers))
print("\tMEDIAN", statistics.median(numbers))
print("\tMEAN ", statistics.mean(numbers))
print("\tSTDEV ", statistics.stdev(numbers))
I ran this on my PostgreSQL 11.1 on my MacBook Pro with Django 2.1.7. So the database is on localhost.
The results
276
True
True
True
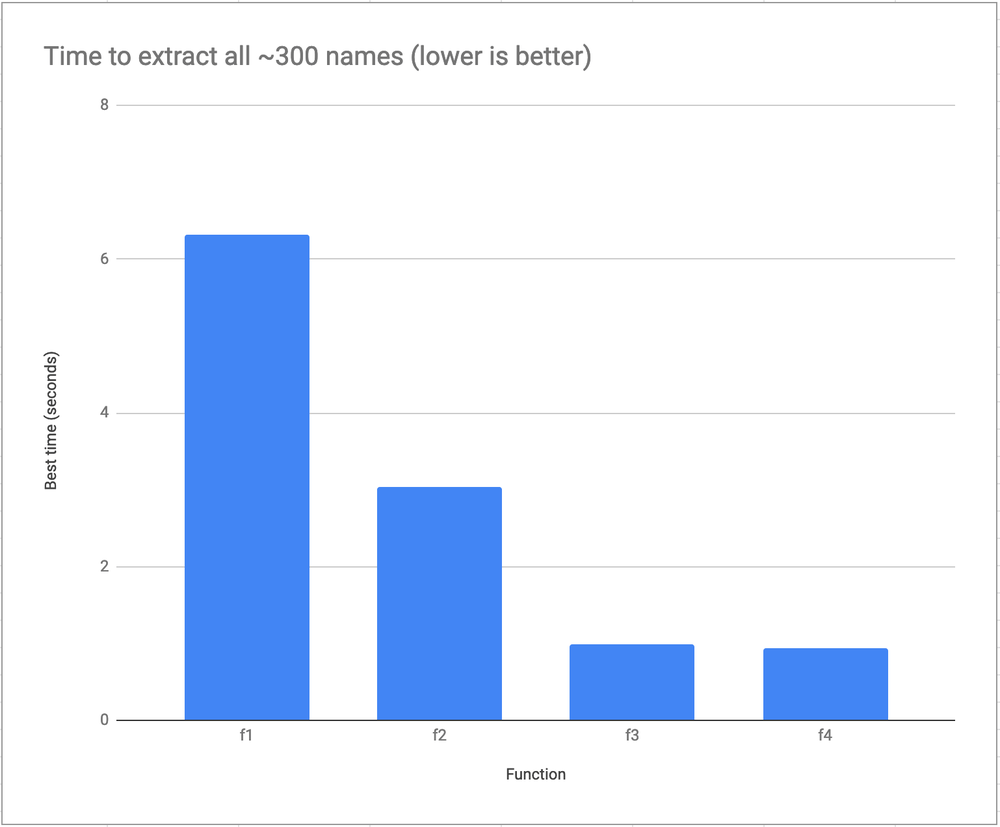
FUNCTION: f1 Used 135 times
BEST 6.309986114501953
MEDIAN 7.531881332397461
MEAN 7.834429211086697
STDEV 2.03779968066591
FUNCTION: f2 Used 135 times
BEST 3.039121627807617
MEDIAN 3.7298202514648438
MEAN 4.012803678159361
STDEV 1.8498943539073027
FUNCTION: f3 Used 110 times
BEST 0.9920597076416016
MEDIAN 1.4405250549316406
MEAN 1.5053835782137783
STDEV 0.3523240470133114
FUNCTION: f4 Used 120 times
BEST 0.9369850158691406
MEDIAN 1.3251304626464844
MEAN 1.4017681280771892
STDEV 0.3391019435930447
Discussion
I guess the hashlib.md5("".join(names).encode("utf-8")).hexdigest() stuff is a bit "off-topic" but I checked and it's roughly 300 times faster than building up the names list.
It's clearly better to ask less of Python and PostgreSQL to get a better total time. No surprise there. What was interesting was the proportion of these differences. Memorize that and you'll be better equipped if it's worth the hassle of not using the Django ORM in the most basic form.
Also, do take note that this is only relevant in when dealing with many records. The slowest variant (f1) takes, on average, 7 milliseconds.
Summarizing the difference with percentages compared to the fastest variant:
f1- 573% slowerf2- 225% slowerf3- 6% slowerf4- 0% slower
from Planet Python
via read more



No comments:
Post a Comment