This article looks at how to work with static and media files in a Django project, locally and in production.
from Planet Python
via read more
Tuesday, February 8, 2022
ItsMyCode: AttributeError: Can only use .str accessor with string values
The AttributeError: Can only use .str accessor with string values, which use np.object_ dtype in pandas occurs if you try to replace the values of string column, but in reality, it is of a different type.
In this tutorial, we will look at what is AttributeError: Can only use .str accessor with string values and how to fix this error with examples.
AttributeError: Can only use .str accessor with string values, which use np.object_ dtype in pandas
Let us take a simple example to reproduce this error. In the below example, we have Pandas DataFrame, which indicates the standing of each cricket team.
# import pandas library
import pandas as pd
# create pandas DataFrame
df = pd.DataFrame({'team': ['India', 'South Africa', 'New Zealand', 'England'],
'points': [12.0, 8.0, 3.0, 5],
'runrate': [0.5, 1.4, 2, -0.6],
'wins': [5, 4, 2, 2]})
print(df['points'])
df['points'] = df['points'].str.replace('.', '')
print(df['points'])
Output
0 12.0
1 8.0
2 3.0
3 5.0
Name: points, dtype: float64
raise AttributeError("Can only use .str accessor with string values!")
AttributeError: Can only use .str accessor with string values!. Did you mean: 'std'?When we run the above code, we get AttributeError Can only use .str accessor with string values!.
The points column is in the float datatype, and using the str.replace() can be applied only on the string columns.
How to fix Can only use .str accessor with string values error?
We can fix the error by casting the DataFrame column “points” from float to string before replacing the values in the column.
Let us fix our code and run it once again.
# import pandas library
import pandas as pd
# create pandas DataFrame
df = pd.DataFrame({'team': ['India', 'South Africa', 'New Zealand', 'England'],
'points': [12.0, 8.0, 3.0, 5],
'runrate': [0.5, 1.4, 2, -0.6],
'wins': [5, 4, 2, 2]})
print(df['points'])
df['points'] = df['points'].astype(str).str.replace('.', '')
print(df['points'])
Output
0 12.0
1 8.0
2 3.0
3 5.0
Name: points, dtype: float64
0 120
1 80
2 30
3 50
Name: points, dtype: objectNotice that the error is gone, and the points column is converted from float to object, and also, the decimal has been replaced with an empty string.
Conclusion
The AttributeError: Can only use .str accessor with string values, which use np.object_ dtype in pandas occurs if you try to replace the values of string column, but in reality, it is of a different type.
We can fix the issue by casting the column to a string before replacing the values in the column.
from Planet Python
via read more
Monday, February 7, 2022
Glyph Lefkowitz: A Better Pygame Mainloop
I’ve written about this before, but in that context I was writing mainly about frame-rate independence, and only gave a brief mention of vertical sync; the title also mentioned Twisted, and upon re-reading it I realized that many folks who might get a lot of use out of its technique would not have bothered to read it, just because I made it sound like an aside in the context of an animation technique in a game that already wanted to use Twisted for some reason, rather than a comprehensive best practice. Now that Pygame 2.0 is out, though, and the vsync=1 flag is more reliably available to everyone, I thought it would be worth revisiting.
Per the many tutorials out there, including the official one, most Pygame mainloops look like this:
1 2 3 4 5 6 7 8 |
|
Obviously that works okay, or folks wouldn’t do it, but it can give an impression of a certain lack of polish for most beginner Pygame games.
The thing that’s always bothered me personally about this idiom is: where does the networking go? After spending many years trying to popularize event loops in Python, I’m sad to see people implementing loops over and over again that have no way to get networking, or threads, or timers scheduled in a standard way so that libraries could be written without the application needing to manually call them every frame.
But, who cares how I feel about it? Lots of games don’t have networking1. There are more general problems with it. Specifically, it is likely to:
- waste power, and
- look bad.
Wasting Power
Why should anyone care about power when they’re making a video game? Aren’t games supposed to just gobble up CPUs and GPUs for breakfast, burning up as much power as they need for the most gamer experience possible?
Chances are, if you’re making a game that you expect anyone that you don’t personally know to play, they’re going to be playing it on a laptop2. Pygame might have a reputation for being “slow”, but for a simple 2D game with only a few sprites, Python can easily render several thousand frames per second. Even the fastest display in the world can only refresh at 360Hz3. That’s less than one thousand frames per second. The average laptop display is going to be more like 60Hz, or — if you’re lucky — maybe 120. By rendering thousands of frames that the user never even sees, you warm up their CPU uncomfortably4, and you waste 10x (or more) of their battery doing useless work.
At some point your game might have enough stuff going on that it will run the CPU at full tilt, and if it does, that’s probably fine; at least then you’ll be using up that heat and battery life in order to make their computer do something useful. But even if it is, it’s probably not doing that all of the time, and battery is definitely a use-over-time sort of problem.
Looking Bad
If you’re rendering directly to the screen without regard for vsync, your players are going to experience Screen Tearing, where the screen is in the middle of updating while you’re in the middle of drawing to it. This looks especially bad if your game is panning over a background, which is a very likely scenario for the usual genre of 2D Pygame game.
How to fix it?
Pygame lets you turn on VSync, and in Pygame 2, you can do this simply by passing the pygame.SCALED flag and the vsync=1 argument to set_mode().
Now your game will have silky smooth animations and scrolling5! Solved!
But... if the fix is so simple, why doesn’t everybody — including, notably, the official documentation — recommend doing this?
The solution creates another problem: pygame.display.flip may now block until the next display refresh, which may be many milliseconds.
Even worse: note the word “may”. Unfortunately, behavior of vsync is quite inconsistent between platforms and drivers, so for a properly cross-platform game it may be necessary to allow the user to select a frame rate and wait on an asyncio.sleep than running flip in a thread. Using the techniques from the answers to this stack overflow answer you can establish a reasonable heuristic for the refresh rate of the relevant display, but if adding those libraries and writing that code is too complex, “60” is probably a good enough value to start with, even if the user’s monitor can go a little faster. This might save a little power even in the case where you can rely on flip to tell you when the monitor is actually ready again; if your game can only reliably render 60FPS anyway because there’s too much Python game logic going on to consistently go faster, it’s better to achieve a consistent but lower framerate than to be faster but inconsistent.
The potential for blocking needs to be dealt with though, and it has several knock-on effects.
For one thing, it makes my “where do you put the networking” problem even worse: most networking frameworks expect to be able to send more than one packet every 16 milliseconds.
More pressingly for most Pygame users, however, it creates a minor performance headache. You now spend a bunch of time blocked in the now-blocking flip call, wasting precious milliseconds that you could be using to do stuff unrelated to drawing, like handling user input, updating animations, running AI, and so on.
The problem is that your Pygame mainloop has 3 jobs:
- drawing
- game logic (AI and so on)
- input handling
What you want to do to ensure the smoothest possible frame rate is to draw everything as fast as you possibly can at the beginning of the frame and then call flip immediately to be sure that the graphics have been delivered to the screen and they don’t have to wait until the next screen-refresh. However, this is at odds with the need to get as much done as possible before you call flip and possibly block for 1/60th of a second.
So either you put off calling flip, potentially risking a dropped frame if your AI is a little slow, or you call flip too eagerly and waste a bunch of time waiting around for the display to refresh. This is especially true of things like animations, which you can’t update before drawing, because you have to draw this frame before you worry about the next one, but waiting until after flip wastes valuable time; by the time you are starting your next frame draw, you possibly have other code which now needs to run, and you’re racing to get it done before that next flip call.
Now, if your Python game logic is actually saturating your CPU — which is not hard to do — you’ll drop frames no matter what. But there are a lot of marginal cases where you’ve mostly got enough CPU to do what you need to without dropping frames, and it can be a lot of overhead to constantly check the clock to see if you have enough frame budget left to do one more work item before the frame deadline - or, for that matter, to maintain a workable heuristic for exactly when that frame deadline will be.
The technique to avoid these problems is deceptively simple, and in fact it was covered with the deferToThread trick presented in my earlier post. But again, we’re not here to talk about Twisted. So let’s do this the no-additional-dependencies, stdlib-only way, with asyncio:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
Go Forth and Loop Better
At some point I will probably release my own wrapper library6 which does something similar to this, but I really wanted to present this as a technique rather than as some packaged-up code to use, since do-it-yourself mainloops, and keeping dependencies to a minimum, are such staples of Pygame community culture.
As you can see, this technique is only a few lines longer than the standard recipe for a Pygame main loop, but you now have access to a ton of additional functionality:
- You can manage your framerate independence in both animations and game logic by just setting some timers and letting the frames update at the appropriate times; stop worrying about doing math on the clock by yourself!
- Do you want to add networked multiplayer? No problem! Networking all happens inside the event loop, make whatever network requests you want, and never worry about blocking the game’s drawing on a network request!
- Now your players’ laptops run cool while playing, and the graphics don’t have ugly tearing artifacts any more!
I really hope that this sees broader adoption so that the description “indie game made in Python” will no longer imply “runs hot and tears a lot when the screen is panning”. I’m also definitely curious to hear from readers, so please let me know if you end up using this technique to good effect!7
-
And, honestly, a few fewer could stand to have it, given how much unnecessary always-online stuff there is in single-player experiences these days. But I digress. That’s why I’m in a footnote, this is a good place for digressing. ↩
-
“Worldwide sales of laptops have eclipsed desktops for more than a decade. In 2019, desktop sales totaled 88.4 million units compared to 166 million laptops. That gap is expected to grow to 79 million versus 171 million by 2023.” ↩
-
At least, Nvidia says that “the world’s fastest esports displays” are both 360Hz and also support G-Sync, and who am I to disagree? ↩
-
They’re playing on a laptop, remember? So they’re literally uncomfortable. ↩
-
Assuming you’ve made everything frame-rate independent, as mentioned in the aforementioned post. ↩
-
because of course I will ↩
-
And also, like, if there are horrible bugs in this code, so I can update it. It is super brief and abstract to show how general it is, but that also means it’s not really possible to test it as-is; my full-working-code examples are much longer and it’s definitely possible something got lost in translation. ↩
from Planet Python
via read more
Stack Abuse: Numpy Array to Tensor and Tensor to Numpy Array with PyTorch
Tensors are multi-dimensional objects, and the essential data representaion block of Deep Learning frameworks such as Tensorflow and PyTorch.
A scalar has one dimension, a vector has two, and tensors have three or more. In practice, we oftentimes refer to scalars and vectors as tensors as well for convinience.
Note: A tensor can also be any n-dimensional array, just like a Numpy array can. Many frameworks have support for working with Numpy arrays, and many of them are built on top of Numpy so the integration is both natural and efficient.
However, a torch.Tensor has more built-in capabilities than Numpy arrays do, and these capabilities are geared towards Deep Learning applications (such as GPU acceleration), so it makes sense to prefer torch.Tensor instances over regular Numpy arrays when working with PyTorch. Additionally, torch.Tensors have a very Numpy-like API, making it intuitive for most with prior experience!
In this guide, learn how to convert between a Numpy Array and PyTorch Tensors.
Convert Numpy Array to PyTorch Tensor
To convert a Numpy array to a PyTorch tensor - we have two distinct approaches we could take: using the from_numpy() function, or by simply supplying the Numpy array to the torch.Tensor() constructor or by using the tensor() function:
import torch
import numpy as np
np_array = np.array([5, 7, 1, 2, 4, 4])
# Convert Numpy array to torch.Tensor
tensor_a = torch.from_numpy(np_array)
tensor_b = torch.Tensor(np_array)
tensor_c = torch.tensor(np_array)
So, what's the difference? The from_numpy() and tensor() functions are dtype-aware! Since we've created a Numpy array of integers, the dtype of the underlying elements will naturally be int32:
print(np_array.dtype)
# dtype('int32')
If we were to print out our two tensors:
print(f'tensor_a: {tensor_a}\ntensor_b: {tensor_b}\ntensor_c: {tensor_c}')
tensor_a and tensor_c retain the data type used within the np_array, cast into PyTorch's variant (torch.int32), while tensor_b automatically assigns the values to floats:
tensor_a: tensor([5, 7, 1, 2, 4, 4], dtype=torch.int32)
tensor_b: tensor([5., 7., 1., 2., 4., 4.])
tensor_c: tensor([5, 7, 1, 2, 4, 4], dtype=torch.int32)
This can also be observed through checking their dtype fields:
print(tensor_a.dtype) # torch.int32
print(tensor_b.dtype) # torch.float32
print(tensor_c.dtype) # torch.int32
Numpy Array to PyTorch Tensor with dtype
These approaches also differ in whether you can explicitly set the desired dtype when creating the tensor. from_numpy() and Tensor() don't accept a dtype argument, while tensor() does:
# Retains Numpy dtype
tensor_a = torch.from_numpy(np_array)
# Creates tensor with float32 dtype
tensor_b = torch.Tensor(np_array)
# Retains Numpy dtype OR creates tensor with specified dtype
tensor_c = torch.tensor(np_array, dtype=torch.int32)
print(tensor_a.dtype) # torch.int32
print(tensor_b.dtype) # torch.float32
print(tensor_c.dtype) # torch.int32
Naturally, you can cast any of them very easily, using the exact same syntax, allowing you to set the dtype after the creation as well, so the acceptance of a dtype argument isn't a limitation, but more of a convenience:
tensor_a = tensor_a.float()
tensor_b = tensor_b.float()
tensor_c = tensor_c.float()
print(tensor_a.dtype) # torch.float32
print(tensor_b.dtype) # torch.float32
print(tensor_c.dtype) # torch.float32
Convert PyTorch Tensor to Numpy Array
Converting a PyTorch Tensor to a Numpy array is straightforward, since tensors are ultimately built on top of Numpy arrays, and all we have to do is "expose" the underlying data structure.
Since PyTorch can optimize the calculations performed on data based on your hardware, there are a couple of caveats though:
tensor = torch.tensor([1, 2, 3, 4, 5])
np_a = tensor.numpy()
np_b = tensor.detach().numpy()
np_c = tensor.detach().cpu().numpy()
So, why use
detach()andcpu()before exposing the underlying data structure withnumpy(), and when should you detach and transfer to a CPU?
CPU PyTorch Tensor -> CPU Numpy Array
If your tensor is on the CPU, where the new Numpy array will also be - it's fine to just expose the data structure:
np_a = tensor.numpy()
# array([1, 2, 3, 4, 5], dtype=int64)
This works very well, and you've got yourself a clean Numpy array.
CPU PyTorch Tensor with Gradients -> CPU Numpy Array
However, if your tensor requires you to calculate gradients for it as well (i.e. the requires_grad argument is set to True), this approach won't work anymore. You'll have to detach the underlying array from the tensor, and through detaching, you'll be pruning away the gradients:
tensor = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float32, requires_grad=True)
np_a = tensor.numpy()
# RuntimeError: Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
np_b = tensor.detach().numpy()
# array([1., 2., 3., 4., 5.], dtype=float32)
GPU PyTorch Tensor -> CPU Numpy Array
Finally - if you've created your tensor on the GPU, it's worth remembering that regular Numpy arrrays don't support GPU acceleration. They reside on the CPU! You'll have to transfer the tensor to a CPU, and then detach/expose the data structure.
Note: This can either be done via the to('cpu') or cpu() functions - they're functionally equivalent.
This has to be done explicitly, because if it were done automatically - the conversion between CPU and CUDA tensors to arrays would be different under the hood, which could lead to unexpected bugs down the line.
PyTorch is fairly explicit, so this sort of automatic conversion was purposefully avoided:
# Create tensor on the GPU
tensor = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float32, requires_grad=True).cuda()
np_b = tensor.detach().numpy()
# TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
np_c = tensor.detach().cpu().numpy()
# array([1., 2., 3., 4., 5.], dtype=float32)
Note: It's highly advised to call detach() before cpu(), to prune away the gradients before transfering to the CPU. The gradients won't matter anyway after the detach() call - so copying them at any point is totally redundant and inefficient. It's better to "cut the dead weight" as soon as possible.
Generally speaking - this approach is the safest, as no matter which sort of tensor you're working - it won't fail. If you've got a CPU tensor, and you try sending it to the CPU - nothing happens. If you've got a tensor without gradients, and try detaching it - nothing happens. On the other end of the stick - exceptions are thrown.
Conclusion
In this guide - we've taken a look at what PyTorch tensors are, before diving into how to convert a Numpy array into a PyTorch tensor. Finally, we've explored how PyTorch tensors can expose the underlying Numpy array, and in which cases you'd have to perform additional transfers and pruning.
from Planet Python
via read more
Matt Layman: Episode 16 - Setting Your Sites
On this episode, we look at how to manage settings on your Django site. What are the common techniques to make this easier to handle? Let’s find out! Listen at djangoriffs.com or with the player below. Last Episode On the last episode, we dug into sessions and how Django uses that data storage technique for visitors to your site. How Is Django Configured? To run properly, Django needs to be configured.
from Planet Python
via read more
from Planet Python
via read more
Python News: What's New From January 2022?
In January 2022, the code formatter Black saw its first non-beta release and published a new stability policy. IPython, the powerful interactive Python shell, marked the release of version 8.0, its first major version release in three years. Additionally, PEP 665, aimed at making reproducible installs easier by specifying a format for lock files, was rejected. Last but not least, a fifteen-year-old memory leak bug in Python was fixed.
Let’s dive into the biggest Python news stories from the past month!
Free Bonus: Click here to get a Python Cheat Sheet and learn the basics of Python 3, like working with data types, dictionaries, lists, and Python functions.
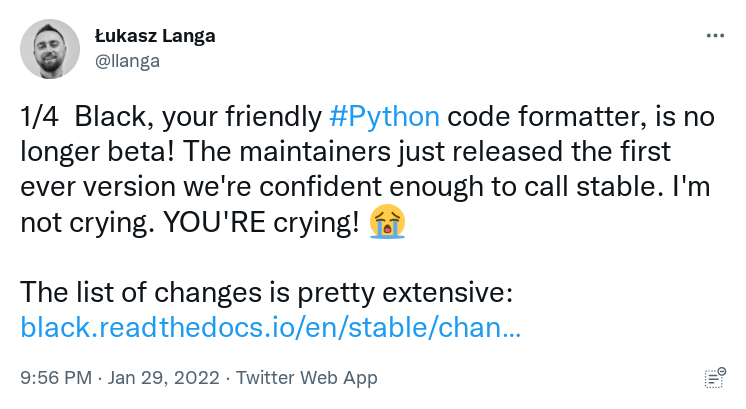
Black No Longer Beta
The developers of Black, an opinionated code formatter, are now confident enough to call the latest release stable. This announcement brings Black out of beta for the first time:
Code formatting can be the source of a surprising amount of conflict among developers. This is why code formatters, or linters, help enforce style conventions to maintain consistency across a whole codebase. Linters suggest changes, while code formatters rewrite your code:
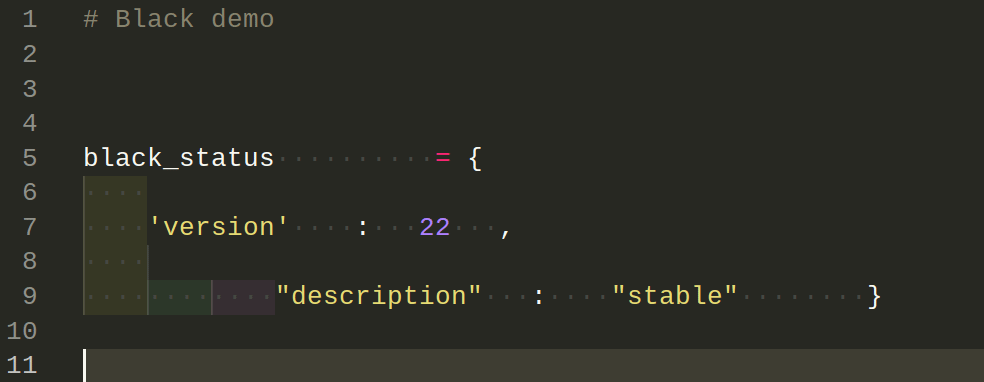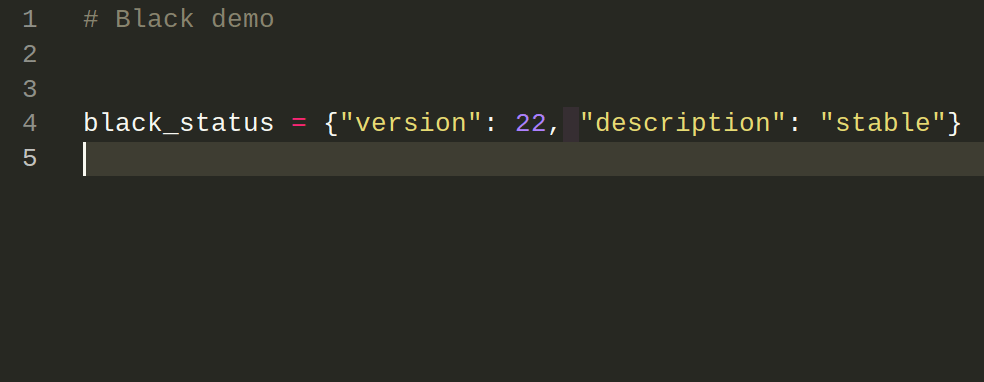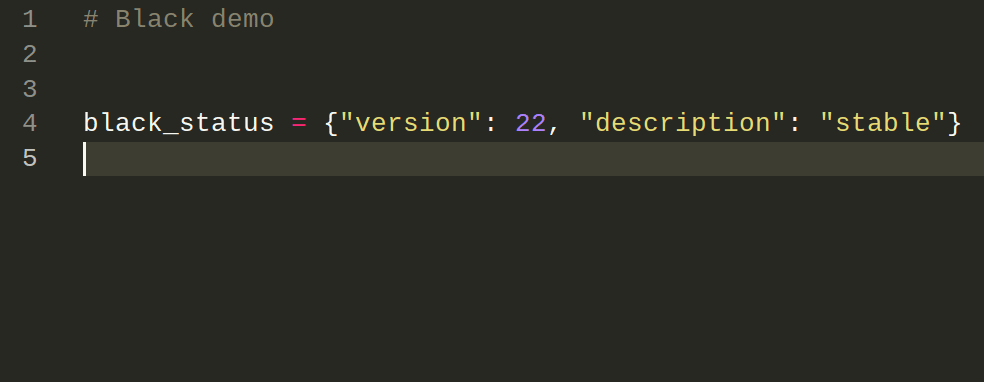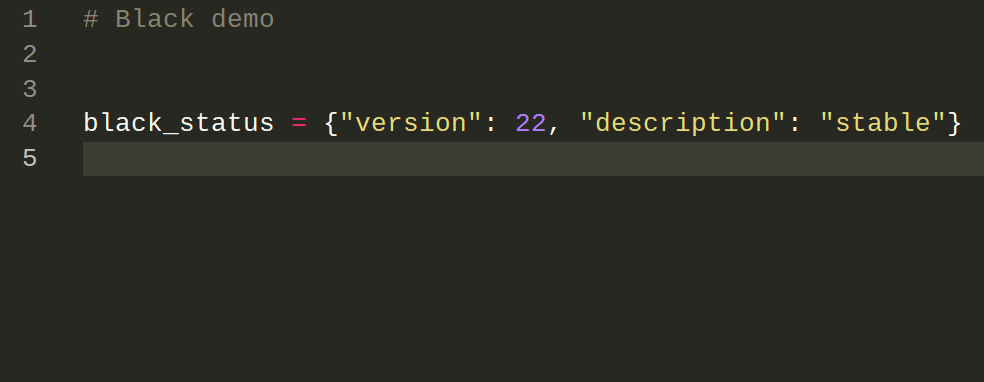
This makes your codebase more consistent, helps catch errors early, and makes code easier to scan.
YAPF is an example of a formatter. It comes with the PEP 8 style guide as a default, but it’s not strongly opinionated, giving you a lot of control over its configuration.
Black goes further: it comes with a PEP 8 compliant style, but on the whole, it’s not configurable. The idea behind disallowing configuration is that you free up your brain to focus on the actual code by relinquishing control over style. Many believe this restriction gives them much more freedom to be creative coders. But of course, not everyone likes to give up this control!
One crucial feature of opinionated formatters like Black is that they make your diffs much more informative. If you’ve ever committed a cleanup or formatting commit to your version control system, you may have inadvertently polluted your diff.
Read the full article at https://realpython.com/python-news-january-2022/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
from Real Python
read more
Mike Driscoll: PyDev of the Week: Batuhan Taskaya
This week we welcome Batuhan Taskaya (@isidentical) as our PyDev of the Week! Batuhan is a core developer of the Python language. Batuhan is also a maintainer of multiple Python packages including parso and Black.
You can see what else Batuhan is up to by checking out his website or GitHub profile.
Let's take a few moments to get to know Batuhan better!
Can you tell us a little about yourself (hobbies, education, etc):
Hey there! My name is Batuhan, and I'm a software engineer who loves to work on developer tools to improve the overall productivity of the Python ecosystem.
I pretty much fill all my free time with open source maintenance and other programming related activities. If I am not programming at that time, I am probably reading a paper about PLT or watching some sci-fi show. I am a huge fan of the Stargate franchise.
Why did you start using Python?
I was always intrigued by computers but didn't do anything related to programming until I started using GNU/Linux on my personal computer (namely Ubuntu 12.04). Back then, I was searching for something to pass the time and found Python.
Initially, I was mind-blown by the responsiveness of the REPL. I typed `2 + 2`, it replied `4` back to me. Such a joy! For someone with literally zero programming experience, it was a very friendly environment. Later, I started following some tutorials, writing more code and repeating that process until I got a good grasp of the Python language and programming in general.
What other programming languages do you know and which is your favourite?
After being exposed to the level of elegancy and the simplicity in Python, I set the bar too high for adopting a new language. C is a great example where the language (in its own terms) is very straightforward, and currently, it is the only language I actively use apart from Python. I also think it goes really well when paired with Python, which might not be surprised considering the CPython itself and the extension modules are written in C.
If we let the mainstream languages go, I love building one-off compilers for weird/esoteric languages.
What projects are you working on now?
Most of my work revolves around CPython, which is the reference implementation of the Python language. In terms of the core, I specialize in the parser and the compiler. But outside of it, I maintain the ast module, and a few others.
One of the recent changes I've collaborated (with Pablo Galindo Salgado an Ammar Askar) on CPython was the new fancy tracebacks which I hope will really increase the productivity of the Python developers:
Traceback (most recent call last):
File "query.py", line 37, in <module>
magic_arithmetic('foo')
^^^^^^^^^^^^^^^^^^^^^^^
File "query.py", line 18, in magic_arithmetic
return add_counts(x) / 25
^^^^^^^^^^^^^
File "query.py", line 24, in add_counts
return 25 + query_user(user1) + query_user(user2)
^^^^^^^^^^^^^^^^^
File "query.py", line 32, in query_user
return 1 + query_count(db, response['a']['b']['c']['user'], retry=True)
~~~~~~~~~~~~~~~~~~^^^^^
TypeError: 'NoneType' object is not subscriptable
Alongside that, I help maintain projects like
and I am a core member of the fsspec.
Which Python libraries are your favorite (core or 3rd party)?
It might be a bit obvious, but I love the ast module. Apart from that, I enjoy using dataclasses and pathlib.
I generally avoid using dependencies since nearly %99 of the time, I can simply use the stdlib. But there is one exception, rich. For the last three months, nearly every script I've written uses it. It is such a beauty (both in terms of the UI and the API). I also really love pytest and pre-commit.
Not as a library, though one of my favorite projects from the python ecosystem is PyPy. It brings an entirely new python runtime, which depending on your work can be 1000X faster (or just 4X in general).
Is there anything else you’d like to say?
I've recently started a GitHub Sponsors Page, and if any of my work directly touches you (or your company) please consider sponsoring me!
Thanks for the interview Mike, and I hope people reading the article enjoyed it as much as I enjoyed answering these questions!
Thanks for doing the interview, Batuhan!
The post PyDev of the Week: Batuhan Taskaya appeared first on Mouse Vs Python.
from Planet Python
via read more
Python GUIs: Packaging PyQt5 applications into a macOS app with PyInstaller (updated for 2022)
There is not much fun in creating your own desktop applications if you can't share them with other people — whether than means publishing it commercially, sharing it online or just giving it to someone you know. Sharing your apps allows other people to benefit from your hard work!
The good news is there are tools available to help you do just that with your Python applications which work well with apps built using PyQt5. In this tutorial we'll look at the most popular tool for packaging Python applications: PyInstaller.
This tutorial is broken down into a series of steps, using PyInstaller to build first simple, and then more complex PyQt5 applications into distributable macOS app bundles. You can choose to follow it through completely, or skip to the parts that are most relevant to your own project.
We finish off by building a macOS Disk Image, the usual method for distributing applications on macOS.
You always need to compile your app on your target system. So, if you want to create a Mac .app you need to do this on a Mac, for an EXE you need to use Windows.
 Example Disk Image Installer for macOS
Example Disk Image Installer for macOS
If you're impatient, you can download the Example Disk Image for macOS first.
Requirements
PyInstaller works out of the box with PyQt5 and as of writing, current versions of PyInstaller are compatible with Python 3.6+. Whatever project you're working on, you should be able to package your apps.
You can install PyInstaller using pip.
bash
pip3 install PyInstaller
If you experience problems packaging your apps, your first step should always be to update your PyInstaller and hooks package the latest versions using
bash
pip3 install --upgrade PyInstaller pyinstaller-hooks-contrib
The hooks module contains package-specific packaging instructions for PyInstaller which is updated regularly.
Install in virtual environment (optional)
You can also opt to install PyQt5 and PyInstaller in a virtual environment (or your applications virtual environment) to keep your environment clean.
bash
python3 -m venv packenv
Once created, activate the virtual environment by running from the command line —
bash
call packenv\scripts\activate.bat
Finally, install the required libraries. For PyQt5 you would use —
python
pip3 install PyQt5 PyInstaller
Getting Started
It's a good idea to start packaging your application from the very beginning so you can confirm that packaging is still working as you develop it. This is particularly important if you add additional dependencies. If you only think about packaging at the end, it can be difficult to debug exactly where the problems are.
For this example we're going to start with a simple skeleton app, which doesn't do anything interesting. Once we've got the basic packaging process working, we'll extend the application to include icons and data files. We'll confirm the build as we go along.
To start with, create a new folder for your application and then add the following skeleton app in a file named app.py. You can also download the source code and associated files
python
from PyQt5 import QtWidgets
import sys
class MainWindow(QtWidgets.QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Hello World")
l = QtWidgets.QLabel("My simple app.")
l.setMargin(10)
self.setCentralWidget(l)
self.show()
if __name__ == '__main__':
app = QtWidgets.QApplication(sys.argv)
w = MainWindow()
app.exec()
This is a basic bare-bones application which creates a custom QMainWindow and adds a simple widget QLabel to it. You can run this app as follows.
bash
python app.py
This should produce the following window (on macOS).
 Simple skeleton app in PyQt5
Simple skeleton app in PyQt5
Building a basic app
Now we have our simple application skeleton in place, we can run our first build test to make sure everything is working.
Open your terminal (command prompt) and navigate to the folder containing your project. You can now run the following command to run the PyInstaller build.
python
pyinstaller --windowed app.py
The --windowed flag is neccessary to tell PyInstaller to build a macOS .app bundle.
You'll see a number of messages output, giving debug information about what PyInstaller is doing. These are useful for debugging issues in your build, but can otherwise be ignored. The output that I get for running the command on my system is shown below.
bash
martin@MacBook-Pro pyqt5 % pyinstaller --windowed app.py
74 INFO: PyInstaller: 4.8
74 INFO: Python: 3.9.9
83 INFO: Platform: macOS-10.15.7-x86_64-i386-64bit
84 INFO: wrote /Users/martin/app/pyqt5/app.spec
87 INFO: UPX is not available.
88 INFO: Extending PYTHONPATH with paths
['/Users/martin/app/pyqt5']
447 INFO: checking Analysis
451 INFO: Building because inputs changed
452 INFO: Initializing module dependency graph...
455 INFO: Caching module graph hooks...
463 INFO: Analyzing base_library.zip ...
3914 INFO: Processing pre-find module path hook distutils from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks/pre_find_module_path/hook-distutils.py'.
3917 INFO: distutils: retargeting to non-venv dir '/usr/local/Cellar/python@3.9/3.9.9/Frameworks/Python.framework/Versions/3.9/lib/python3.9'
6928 INFO: Caching module dependency graph...
7083 INFO: running Analysis Analysis-00.toc
7091 INFO: Analyzing /Users/martin/app/pyqt5/app.py
7138 INFO: Processing module hooks...
7139 INFO: Loading module hook 'hook-PyQt6.QtWidgets.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7336 INFO: Loading module hook 'hook-xml.etree.cElementTree.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7337 INFO: Loading module hook 'hook-lib2to3.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7360 INFO: Loading module hook 'hook-PyQt6.QtGui.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7397 INFO: Loading module hook 'hook-PyQt6.QtCore.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7422 INFO: Loading module hook 'hook-encodings.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7510 INFO: Loading module hook 'hook-distutils.util.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7513 INFO: Loading module hook 'hook-pickle.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7515 INFO: Loading module hook 'hook-heapq.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7517 INFO: Loading module hook 'hook-difflib.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7519 INFO: Loading module hook 'hook-PyQt6.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7564 INFO: Loading module hook 'hook-multiprocessing.util.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7565 INFO: Loading module hook 'hook-sysconfig.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7574 INFO: Loading module hook 'hook-xml.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7677 INFO: Loading module hook 'hook-distutils.py' from '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks'...
7694 INFO: Looking for ctypes DLLs
7712 INFO: Analyzing run-time hooks ...
7715 INFO: Including run-time hook '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py'
7719 INFO: Including run-time hook '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py'
7722 INFO: Including run-time hook '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks/rthooks/pyi_rth_multiprocessing.py'
7726 INFO: Including run-time hook '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks/rthooks/pyi_rth_inspect.py'
7727 INFO: Including run-time hook '/usr/local/lib/python3.9/site-packages/PyInstaller/hooks/rthooks/pyi_rth_pyqt6.py'
7736 INFO: Looking for dynamic libraries
7977 INFO: Looking for eggs
7977 INFO: Using Python library /usr/local/Cellar/python@3.9/3.9.9/Frameworks/Python.framework/Versions/3.9/Python
7987 INFO: Warnings written to /Users/martin/app/pyqt5/build/app/warn-app.txt
8019 INFO: Graph cross-reference written to /Users/martin/app/pyqt5/build/app/xref-app.html
8032 INFO: checking PYZ
8035 INFO: Building because toc changed
8035 INFO: Building PYZ (ZlibArchive) /Users/martin/app/pyqt5/build/app/PYZ-00.pyz
8390 INFO: Building PYZ (ZlibArchive) /Users/martin/app/pyqt5/build/app/PYZ-00.pyz completed successfully.
8397 INFO: EXE target arch: x86_64
8397 INFO: Code signing identity: None
8398 INFO: checking PKG
8398 INFO: Building because /Users/martin/app/pyqt5/build/app/PYZ-00.pyz changed
8398 INFO: Building PKG (CArchive) app.pkg
8415 INFO: Building PKG (CArchive) app.pkg completed successfully.
8417 INFO: Bootloader /usr/local/lib/python3.9/site-packages/PyInstaller/bootloader/Darwin-64bit/runw
8417 INFO: checking EXE
8418 INFO: Building because console changed
8418 INFO: Building EXE from EXE-00.toc
8418 INFO: Copying bootloader EXE to /Users/martin/app/pyqt5/build/app/app
8421 INFO: Converting EXE to target arch (x86_64)
8449 INFO: Removing signature(s) from EXE
8484 INFO: Appending PKG archive to EXE
8486 INFO: Fixing EXE headers for code signing
8496 INFO: Rewriting the executable's macOS SDK version (11.1.0) to match the SDK version of the Python library (10.15.6) in order to avoid inconsistent behavior and potential UI issues in the frozen application.
8499 INFO: Re-signing the EXE
8547 INFO: Building EXE from EXE-00.toc completed successfully.
8549 INFO: checking COLLECT
WARNING: The output directory "/Users/martin/app/pyqt5/dist/app" and ALL ITS CONTENTS will be REMOVED! Continue? (y/N)y
On your own risk, you can use the option `--noconfirm` to get rid of this question.
10820 INFO: Removing dir /Users/martin/app/pyqt5/dist/app
10847 INFO: Building COLLECT COLLECT-00.toc
12460 INFO: Building COLLECT COLLECT-00.toc completed successfully.
12469 INFO: checking BUNDLE
12469 INFO: Building BUNDLE because BUNDLE-00.toc is non existent
12469 INFO: Building BUNDLE BUNDLE-00.toc
13848 INFO: Moving BUNDLE data files to Resource directory
13901 INFO: Signing the BUNDLE...
16049 INFO: Building BUNDLE BUNDLE-00.toc completed successfully.
If you look in your folder you'll notice you now have two new folders dist and build.
 build & dist folders created by PyInstaller
build & dist folders created by PyInstaller
Below is a truncated listing of the folder content, showing the build and dist folders.
bash
.
&boxvr&boxh&boxh app.py
&boxvr&boxh&boxh app.spec
&boxvr&boxh&boxh build
&boxv &boxur&boxh&boxh app
&boxv &boxvr&boxh&boxh Analysis-00.toc
&boxv &boxvr&boxh&boxh COLLECT-00.toc
&boxv &boxvr&boxh&boxh EXE-00.toc
&boxv &boxvr&boxh&boxh PKG-00.pkg
&boxv &boxvr&boxh&boxh PKG-00.toc
&boxv &boxvr&boxh&boxh PYZ-00.pyz
&boxv &boxvr&boxh&boxh PYZ-00.toc
&boxv &boxvr&boxh&boxh app
&boxv &boxvr&boxh&boxh app.pkg
&boxv &boxvr&boxh&boxh base_library.zip
&boxv &boxvr&boxh&boxh warn-app.txt
&boxv &boxur&boxh&boxh xref-app.html
&boxur&boxh&boxh dist
&boxvr&boxh&boxh app
&boxv &boxvr&boxh&boxh libcrypto.1.1.dylib
&boxv &boxvr&boxh&boxh PyQt5
&boxv ...
&boxv &boxvr&boxh&boxh app
&boxv &boxur&boxh&boxh Qt5Core
&boxur&boxh&boxh app.app
The build folder is used by PyInstaller to collect and prepare the files for bundling, it contains the results of analysis and some additional logs. For the most part, you can ignore the contents of this folder, unless you're trying to debug issues.
The dist (for "distribution") folder contains the files to be distributed. This includes your application, bundled as an executable file, together with any associated libraries (for example PyQt5) and binary .so files.
Since we provided the --windowed flag above, PyInstaller has actually created two builds for us. The folder app is a simple folder containing everything you need to be able to run your app. PyInstaller also creates an app bundle app.app which is what you will usually distribute to users.
The app folder is a useful debugging tool, since you can easily see the libraries and other packaged data files.
You can try running your app yourself now, either by double-clicking on the app bundle, or by running the executable file, named app.exe from the dist folder. In either case, after a short delay you'll see the familiar window of your application pop up as shown below.
Simple app, running after being packaged
In the same folder as your Python file, alongside the build and dist folders PyInstaller will have also created a .spec file. In the next section we'll take a look at this file, what it is and what it does.
The Spec file
The .spec file contains the build configuration and instructions that PyInstaller uses to package up your application. Every PyInstaller project has a .spec file, which is generated based on the command line options you pass when running pyinstaller.
When we ran pyinstaller with our script, we didn't pass in anything other than the name of our Python application file and the --windowed flag. This means our spec file currently contains only the default configuration. If you open it, you'll see something similar to what we have below.
python
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
a = Analysis(['app.py'],
pathex=[],
binaries=[],
datas=[],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
[],
exclude_binaries=True,
name='app',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=False,
disable_windowed_traceback=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None )
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
upx_exclude=[],
name='app')
app = BUNDLE(coll,
name='app.app',
icon=None,
bundle_identifier=None)
The first thing to notice is that this is a Python file, meaning you can edit it and use Python code to calculate values for the settings. This is mostly useful for complex builds, for example when you are targeting different platforms and want to conditionally define additional libraries or dependencies to bundle.
Because we used the --windowed command line flag, the EXE(console=) attribute is set to False. If this is True a console window will be shown when your app is launched -- not what you usually want for a GUI application.
Once a .spec file has been generated, you can pass this to pyinstaller instead of your script to repeat the previous build process. Run this now to rebuild your executable.
bash
pyinstaller app.spec
The resulting build will be identical to the build used to generate the .spec file (assuming you have made no changes). For many PyInstaller configuration changes you have the option of passing command-line arguments, or modifying your existing .spec file. Which you choose is up to you.
Tweaking the build
So far we've created a simple first build of a very basic application. Now we'll look at a few of the most useful options that PyInstaller provides to tweak our build. Then we'll go on to look at building more complex applications.
Naming your app
One of the simplest changes you can make is to provide a proper "name" for your application. By default the app takes the name of your source file (minus the extension), for example main or app. This isn't usually what you want.
You can provide a nicer name for PyInstaller to use for the app (and dist folder) by editing the .spec file to add a name= under the EXE, COLLECT and BUNDLE blocks.
python
exe = EXE(pyz,
a.scripts,
[],
exclude_binaries=True,
name='Hello World',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=False
)
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
upx_exclude=[],
name='Hello World')
app = BUNDLE(coll,
name='Hello World.app',
icon=None,
bundle_identifier=None)
The name under EXE is the name of the executable file, the name under BUNDLE is the name of the app bundle.
Alternatively, you can re-run the pyinstaller command and pass the -n or --name configuration flag along with your app.py script.
bash
pyinstaller -n "Hello World" --windowed app.py
# or
pyinstaller --name "Hello World" --windowed app.py
The resulting app file will be given the name Hello World.app and the unpacked build placed in the folder dist\Hello World\.
Application with custom name "Hello World"
The name of the .spec file is taken from the name passed in on the command line, so this will also create a new spec file for you, called Hello World.spec in your root folder.
Make sure you delete the old app.spec file to avoid getting confused editing the wrong one.
Application icon
By default PyInstaller app bundles come with the following icon in place.
![]() Default PyInstaller application icon, on app bundle
Default PyInstaller application icon, on app bundle
You will probably want to customize this to make your application more recognisable. This can be done easily by passing the --icon command line argument, or editing the icon= parameter of the BUNDLE section of your .spec file. For macOS app bundles you need to provide an .icns file.
python
app = BUNDLE(coll,
name='Hello World.app',
icon='Hello World.icns',
bundle_identifier=None)
To create macOS icons from images you can use the image2icon tool.
If you now re-run the build (by using the command line arguments, or running with your modified .spec file) you'll see the specified icon file is now set on your application bundle.
![]() Custom application icon on the app bundle
Custom application icon on the app bundle
On macOS application icons are taken from the application bundle. If you repackage your app and run the bundle you will see your app icon on the dock!
![]() Custom application icon on the dock
Custom application icon on the dock
Data files and Resources
So far our application consists of just a single Python file, with no dependencies. Most real-world applications a bit more complex, and typically ship with associated data files such as icons or UI design files. In this section we'll look at how we can accomplish this with PyInstaller, starting with a single file and then bundling complete folders of resources.
First let's update our app with some more buttons and add icons to each.
python
from PyQt5.QtWidgets import QMainWindow, QApplication, QLabel, QVBoxLayout, QPushButton, QWidget
from PyQt5.QtGui import QIcon
import sys
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Hello World")
layout = QVBoxLayout()
label = QLabel("My simple app.")
label.setMargin(10)
layout.addWidget(label)
button1 = QPushButton("Hide")
button1.setIcon(QIcon("icons/hand.png"))
button1.pressed.connect(self.lower)
layout.addWidget(button1)
button2 = QPushButton("Close")
button2.setIcon(QIcon("icons/lightning.png"))
button2.pressed.connect(self.close)
layout.addWidget(button2)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
self.show()
if __name__ == '__main__':
app = QApplication(sys.argv)
w = MainWindow()
app.exec_()
In the folder with this script, add a folder icons which contains two icons in PNG format, hand.png and lightning.png. You can create these yourself, or get them from the source code download for this tutorial.
Run the script now and you will see a window showing two buttons with icons.
 Window with two buttons with icons.
Window with two buttons with icons.
Even if you don't see the icons, keep reading!
Dealing with relative paths
There is a gotcha here, which might not be immediately apparent. To demonstrate it, open up a shell and change to the folder where our script is located. Run it with
bash
python3 app.py
If the icons are in the correct location, you should see them. Now change to the parent folder, and try and run your script again (change <folder> to the name of the folder your script is in).
bash
cd ..
python3 <folder>/app.py
 Window with two buttons with icons missing.
Window with two buttons with icons missing.
The icons don't appear. What's happening?
We're using relative paths to refer to our data files. These paths are relative to the current working directory -- not the folder your script is in. So if you run the script from elsewhere it won't be able to find the files.
One common reason for icons not to show up, is running examples in an IDE which uses the project root as the current working directory.
This is a minor issue before the app is packaged, but once it's installed it will be started with it's current working directory as the root / folder -- your app won't be able to find anything. We need to fix this before we go any further, which we can do by making our paths relative to our application folder.
In the updated code below, we define a new variable basedir, using os.path.dirname to get the containing folder of __file__ which holds the full path of the current Python file. We then use this to build the relative paths for icons using os.path.join().
Since our app.py file is in the root of our folder, all other paths are relative to that.
python
from PyQt5.QtWidgets import QMainWindow, QApplication, QLabel, QVBoxLayout, QPushButton, QWidget
from PyQt5.QtGui import QIcon
import sys, os
basedir = os.path.dirname(__file__)
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Hello World")
layout = QVBoxLayout()
label = QLabel("My simple app.")
label.setMargin(10)
layout.addWidget(label)
button1 = QPushButton("Hide")
button1.setIcon(QIcon(os.path.join(basedir, "icons", "hand.png")))
button1.pressed.connect(self.lower)
layout.addWidget(button1)
button2 = QPushButton("Close")
button2.setIcon(QIcon(os.path.join(basedir, "icons", "lightning.png")))
button2.pressed.connect(self.close)
layout.addWidget(button2)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
self.show()
if __name__ == '__main__':
app = QApplication(sys.argv)
w = MainWindow()
app.exec_()
Try and run your app again from the parent folder -- you'll find that the icons now appear as expected on the buttons, no matter where you launch the app from.
Packaging the icons
So now we have our application showing icons, and they work wherever the application is launched from. Package the application again with pyinstaller "Hello World.spec" and then try and run it again from the dist folder as before. You'll notice the icons are missing again.
Window with two buttons with icons missing.
The problem now is that the icons haven't been copied to the dist/Hello World folder -- take a look in it. Our script expects the icons to be a specific location relative to it, and if they are not, then nothing will be shown.
This same principle applies to any other data files you package with your application, including Qt Designer UI files, settings files or source data. You need to ensure that relative path structures are replicated after packaging.
Bundling data files with PyInstaller
For the application to continue working after packaging, the files it depends on need to be in the same relative locations.
To get data files into the dist folder we can instruct PyInstaller to copy them over. PyInstaller accepts a list of individual paths to copy, together with a folder path relative to the dist/<app name> folder where it should to copy them to. As with other options, this can be specified by command line arguments or in the .spec file.
Files specified on the command line are added using --add-data, passing the source file and destination folder separated by a colon :.
The path separator is platform-specific: Linux or Mac use :, on Windows use ;
bash
pyinstaller --windowed --name="Hello World" --icon="Hello World.icns" --add-data="icons/hand.png:icons" --add-data="icons/lightning.png:icons" app.py
Here we've specified the destination location as icons. The path is relative to the root of our application's folder in dist -- so dist/Hello World with our current app. The path icons means a folder named icons under this location, so dist/Hello World/icons. Putting our icons right where our application expects to find them!
You can also specify data files via the datas list in the Analysis section of the spec file, shown below.
python
a = Analysis(['app.py'],
pathex=[],
binaries=[],
datas=[('icons/hand.png', 'icons'), ('icons/lightning.png', 'icons')],
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
Then rebuild from the .spec file with
bash
pyinstaller "Hello World.spec"
In both cases we are telling PyInstaller to copy the specified files to the location ./icons/ in the output folder, meaning dist/Hello World/icons. If you run the build, you should see your .png files are now in the in dist output folder, under a folder named icons.
![]() The icon file copied to the dist folder
The icon file copied to the dist folder
If you run your app from dist you should now see the icon icons in your window as expected!
Window with two buttons with icons, finally!
Bundling data folders
Usually you will have more than one data file you want to include with your packaged file. The latest PyInstaller versions let you bundle folders just like you would files, keeping the sub-folder structure.
Let's update our configuration to bundle our icons folder in one go, so it will continue to work even if we add more icons in future.
To copy the icons folder across to our build application, we just need to add the folder to our .spec file Analysis block. As for the single file, we add it as a tuple with the source path (from our project folder) and the destination folder under the resulting folder in dist.
python
# ...
a = Analysis(['app.py'],
pathex=[],
binaries=[],
datas=[('icons', 'icons')], # tuple is (source_folder, destination_folder)
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
# ...
If you run the build using this spec file you'll see the icons folder copied across to the dist\Hello World folder. If you run the application from the folder, the icons will display as expected -- the relative paths remain correct in the new location.
Alternatively, you can bundle your data files using Qt's QResource architecture. See our tutorial for more information.
Building the App bundle into a Disk Image
So far we've used PyInstaller to bundle the application into macOS app, along with the associated data files. The output of this bundling process is a folder and an macOS app bundle, named Hello World.app.
If you try and distribute this app bundle, you'll notice a problem: the app bundle is actually just a special folder. While macOS displays it as an application, if you try and share it, you'll actually be sharing hundreds of individual files. To distribute the app properly, we need some way to package it into a single file.
The easiest way to do this is to use a .zip file. You can zip the folder and give this to someone else to unzip on their own computer, giving them a complete app bundle they can copy to their Applications folder.
However, if you've install macOS applications before you'll know this isn't the usual way to do it. Usually you get a Disk Image .dmg file, which when opened shows the application bundle, and a link to your Applications folder. To install the app, you just drag it across to the target.
To make our app look as professional as possible, we should copy this expected behaviour. Next we'll look at how to take our app bundle and package it into a macOS Disk Image.
Making sure the build is ready.
If you've followed the tutorial so far, you'll already have your app ready in the /dist folder. If not, or yours isn't working you can also download the source code files for this tutorial which includes a sample .spec file. As above, you can run the same build using the provided Hello World.spec file.
bash
pyinstaller "Hello World.spec"
This packages everything up as an app bundle in the dist/ folder, with a custom icon. Run the app bundle to ensure everything is bundled correctly, and you should see the same window as before with the icons visible.
Window with two icons, and a button.
Creating an Disk Image
Now we've successfully bundled our application, we'll next look at how we can take our app bundle and use it to create a macOS Disk Image for distribution.
To create our Disk Image we'll be using the create-dmg tool. This is a command-line tool which provides a simple way to build disk images automatically. If you are using Homebrew, you can install create-dmg with the following command.
bash
brew install create-dmg
...otherwise, see the Github repository for instructions.
The create-dmg tool takes a lot of options, but below are the most useful.
bash
create-dmg --help
create-dmg 1.0.9
Creates a fancy DMG file.
Usage: create-dmg [options] <output_name.dmg> <source_folder>
All contents of <source_folder> will be copied into the disk image.
Options:
--volname <name>
set volume name (displayed in the Finder sidebar and window title)
--volicon <icon.icns>
set volume icon
--background <pic.png>
set folder background image (provide png, gif, or jpg)
--window-pos <x> <y>
set position the folder window
--window-size <width> <height>
set size of the folder window
--text-size <text_size>
set window text size (10-16)
--icon-size <icon_size>
set window icons size (up to 128)
--icon file_name <x> <y>
set position of the file's icon
--hide-extension <file_name>
hide the extension of file
--app-drop-link <x> <y>
make a drop link to Applications, at location x,y
--no-internet-enable
disable automatic mount & copy
--add-file <target_name> <file>|<folder> <x> <y>
add additional file or folder (can be used multiple times)
-h, --help
display this help screen
The most important thing to notice is that the command requires a <source folder> and all contents of that folder will be copied to the Disk Image. So to build the image, we first need to put our app bundle in a folder by itself.
Rather than do this manually each time you want to build a Disk Image I recommend creating a shell script. This ensures the build is reproducible, and makes it easier to configure.
Below is a working script to create a Disk Image from our app. It creates a temporary folder dist/dmg where we'll put the things we want to go in the Disk Image -- in our case, this is just the app bundle, but you can add other files if you like. Then we make sure the folder is empty (in case it still contains files from a previous run). We copy our app bundle into the folder, and finally check to see if there is already a .dmg file in dist and if so, remove it too. Then we're ready to run the create-dmg tool.
bash
#!/bin/sh
# Create a folder (named dmg) to prepare our DMG in (if it doesn't already exist).
mkdir -p dist/dmg
# Empty the dmg folder.
rm -r dist/dmg/*
# Copy the app bundle to the dmg folder.
cp -r "dist/Hello World.app" dist/dmg
# If the DMG already exists, delete it.
test -f "dist/Hello World.dmg" && rm "dist/Hello World.dmg"
create-dmg \
--volname "Hello World" \
--volicon "Hello World.icns" \
--window-pos 200 120 \
--window-size 600 300 \
--icon-size 100 \
--icon "Hello World.app" 175 120 \
--hide-extension "Hello World.app" \
--app-drop-link 425 120 \
"dist/Hello World.dmg" \
"dist/dmg/"
The options we pass to create-dmg set the dimensions of the Disk Image window when it is opened, and positions of the icons in it.
Save this shell script in the root of your project, named e.g. builddmg.sh. To make it possible to run, you need to set the execute bit with.
bash
chmod +x builddmg.sh
With that, you can now build a Disk Image for your Hello World app with the command.
bash
./builddmg.sh
This will take a few seconds to run, producing quite a bit of output.
bash
No such file or directory
Creating disk image...
...............................................................
created: /Users/martin/app/dist/rw.Hello World.dmg
Mounting disk image...
Mount directory: /Volumes/Hello World
Device name: /dev/disk2
Making link to Applications dir...
/Volumes/Hello World
Copying volume icon file 'Hello World.icns'...
Running AppleScript to make Finder stuff pretty: /usr/bin/osascript "/var/folders/yf/1qvxtg4d0vz6h2y4czd69tf40000gn/T/createdmg.tmp.XXXXXXXXXX.RvPoqdr0" "Hello World"
waited 1 seconds for .DS_STORE to be created.
Done running the AppleScript...
Fixing permissions...
Done fixing permissions
Blessing started
Blessing finished
Deleting .fseventsd
Unmounting disk image...
hdiutil: couldn't unmount "disk2" - Resource busy
Wait a moment...
Unmounting disk image...
"disk2" ejected.
Compressing disk image...
Preparing imaging engine…
Reading Protective Master Boot Record (MBR : 0)…
(CRC32 $38FC6E30: Protective Master Boot Record (MBR : 0))
Reading GPT Header (Primary GPT Header : 1)…
(CRC32 $59C36109: GPT Header (Primary GPT Header : 1))
Reading GPT Partition Data (Primary GPT Table : 2)…
(CRC32 $528491DC: GPT Partition Data (Primary GPT Table : 2))
Reading (Apple_Free : 3)…
(CRC32 $00000000: (Apple_Free : 3))
Reading disk image (Apple_HFS : 4)…
...............................................................................
(CRC32 $FCDC1017: disk image (Apple_HFS : 4))
Reading (Apple_Free : 5)…
...............................................................................
(CRC32 $00000000: (Apple_Free : 5))
Reading GPT Partition Data (Backup GPT Table : 6)…
...............................................................................
(CRC32 $528491DC: GPT Partition Data (Backup GPT Table : 6))
Reading GPT Header (Backup GPT Header : 7)…
...............................................................................
(CRC32 $56306308: GPT Header (Backup GPT Header : 7))
Adding resources…
...............................................................................
Elapsed Time: 3.443s
File size: 23178950 bytes, Checksum: CRC32 $141F3DDC
Sectors processed: 184400, 131460 compressed
Speed: 18.6Mbytes/sec
Savings: 75.4%
created: /Users/martin/app/dist/Hello World.dmg
hdiutil does not support internet-enable. Note it was removed in macOS 10.15.
Disk image done
While it's building, the Disk Image will pop up. Don't get too excited yet, it's still building. Wait for the script to complete, and you will find the finished .dmg file in the dist/ folder.
 The Disk Image created in the dist folder
The Disk Image created in the dist folder
Running the installer
Double-click the Disk Image to open it, and you'll see the usual macOS install view. Click and drag your app across the the Applications folder to install it.
The Disk Image contains the app bundle and a shortcut to the applications folder
If you open the Showcase view (press F4) you will see your app installed. If you have a lot of apps, you can search for it by typing "Hello"
 The app installed on macOS
The app installed on macOS
Repeating the build
Now you have everything set up, you can create a new app bundle & Disk Image of your application any time, by running the two commands from the command line.
bash
pyinstaller "Hello World.spec"
./builddmg.sh
It's that simple!
Wrapping up
In this tutorial we've covered how to build your PyQt5 applications into a macOS app bundle using PyInstaller, including adding data files along with your code. Then we walked through the process of creating a Disk Image to distribute your app to others. Following these steps you should be able to package up your own applications and make them available to other people.
For a complete view of all PyInstaller bundling options take a look at the PyInstaller usage documentation.
For more, see the complete PyQt5 tutorial.
from Planet Python
via read more
Sunday, February 6, 2022
Podcast.__init__: Achieve Repeatable Builds Of Your Software On Any Machine With Earthly
It doesn't matter how amazing your application is if you are unable to deliver it to your users. Frustrated with the rampant complexity involved in building and deploying software Vlad A. Ionescu created the Earthly tool to reduce the toil involved in creating repeatable software builds. In this episode he explains the complexities that are inherent to building software projects and how he designed the syntax and structure of Earthly to make it easy to adopt for developers across all language environments. By adopting Earthly you can use the same techniques for building on your laptop and in your CI/CD pipelines.

from Planet Python
via read more
Summary
It doesn’t matter how amazing your application is if you are unable to deliver it to your users. Frustrated with the rampant complexity involved in building and deploying software Vlad A. Ionescu created the Earthly tool to reduce the toil involved in creating repeatable software builds. In this episode he explains the complexities that are inherent to building software projects and how he designed the syntax and structure of Earthly to make it easy to adopt for developers across all language environments. By adopting Earthly you can use the same techniques for building on your laptop and in your CI/CD pipelines.
Announcements
- Hello and welcome to Podcast.__init__, the podcast about Python’s role in data and science.
- When you’re ready to launch your next app or want to try a project you hear about on the show, you’ll need somewhere to deploy it, so take a look at our friends over at Linode. With the launch of their managed Kubernetes platform it’s easy to get started with the next generation of deployment and scaling, powered by the battle tested Linode platform, including simple pricing, node balancers, 40Gbit networking, dedicated CPU and GPU instances, and worldwide data centers. Go to pythonpodcast.com/linode and get a $100 credit to try out a Kubernetes cluster of your own. And don’t forget to thank them for their continued support of this show!
- Your host as usual is Tobias Macey and today I’m interviewing Vlad A. Ionescu about Earthly, a syntax and runtime for software builds to reduce friction between development and delivery
Interview
- Introductions
- How did you get introduced to Python?
- Can you describe what Earthly is and the story behind it?
- What are the core principles that engineers should consider when designing their build and delivery process?
- What are some of the common problems that engineers run into when they are designing their build process?
- What are some of the challenges that are unique to the Python ecosystem?
- What is the role of Earthly in the overall software lifecycle?
- What are the other tools/systems that a team is likely to use alongside Earthly?
- What are the components that Earthly might replace?
- How is Earthly implemented?
- What were the core design requirements when you first began working on it?
- How have the design and goals of Earthly changed or evolved as you have explored the problem further?
- What is the workflow for a Python developer to get started with Earthly?
- How can Earthly help with the challenge of managing Javascript and CSS assets for web application projects?
- What are some of the challenges (technical, conceptual, or organizational) that an engineer or team might encounter when adopting Earthly?
- What are some of the features or capabilities of Earthly that are overlooked or misunderstood that you think are worth exploring?
- What are the most interesting, innovative, or unexpected ways that you have seen Earthly used?
- What are the most interesting, unexpected, or challenging lessons that you have learned while working on Earthly?
- When is Earthly the wrong choice?
- What do you have planned for the future of Earthly?
Keep In Touch
- @VladAIonescu on Twitter
- Website
Picks
- Tobias
- Shape Up book
- Vlad
- High Output Management by Andy Grove
Closing Announcements
- Thank you for listening! Don’t forget to check out our other show, the Data Engineering Podcast for the latest on modern data management.
- Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.
- If you’ve learned something or tried out a project from the show then tell us about it! Email hosts@podcastinit.com) with your story.
- To help other people find the show please leave a review on iTunes and tell your friends and co-workers
Links
- Earthly
- Bazel
- Pants
- ARM
- AWS Graviton
- Apple M1 CPU
- Qemu
- Phoenix web framework for Elixir language
The intro and outro music is from Requiem for a Fish The Freak Fandango Orchestra / CC BY-SA
from Planet Python
via read more
Subscribe to:
Comments (Atom)
-
Podcasts are a great way to immerse yourself in an industry, especially when it comes to data science. The field moves extremely quickly, an...
-
Dialogs are useful GUI components that allow you to communicate with the user (hence the name dialog ). They are commonly used for file Ope...
-
Have you ever wanted to use your python and web development skills to build cross platform desktop GUI apps? if yes then welcome to this tut...

