Here's a question: What's the most common way to explore data? Would you say pandas and matplotlib? Maybe you went more general and said Jupyter notebooks. How about Excel, or Google Sheets, or Numbers, or some other spreadsheet app? Yeah, my bet is on Excel. And while it has many drawbacks, it makes exploring tabular data very accessible to many people, most of whom aren't even developers or data scientists. <br/> <br/> On this episode, we're talking about a tool called Mito. This is an add-in for Jupyter notebooks that injects an Excel-like interface into the notebook. You pass it data via a pandas dataframe (or some other source) and then you can explore it as if you're using Excel. The cool thing is though, just below that, it's writing the pandas code you'd need to do to actually accomplish that outcome in code. <br/> <br/> I think this will make pandas and Python data exploration way more accessible to many more people. So if you've been intimidated by pandas, or know someone who has, this could be what you've been looking for.<br/> <br/> <strong>Links from the show</strong><br/> <br/> <div><b>Mito</b>: <a href="https://www.trymito.io/" target="_blank" rel="noopener">trymito.io</a><br/> <b>Mito summary stats</b>: <a href="https://ift.tt/3xM6Hv5" target="_blank" rel="noopener">trymito.io</a><br/> <b>pandas-profiling package</b>: <a href="https://ift.tt/2EttSgM" target="_blank" rel="noopener">github.com</a><br/> <b>Lux API</b>: <a href="https://ift.tt/3rwqFJ0" target="_blank" rel="noopener">pypi.org</a><br/> <b>Hex notebooks</b>: <a href="https://ift.tt/3o982sT" target="_blank" rel="noopener">medium.com</a><br/> <b>Deepnote</b>: <a href="https://deepnote.com/" target="_blank" rel="noopener">deepnote.com</a><br/> <b>Papermill</b>: <a href="https://ift.tt/3D6gQDT" target="_blank" rel="noopener">papermill.readthedocs.io</a><br/> <b>JupterLite</b>: <a href="https://ift.tt/2UIzTDM" target="_blank" rel="noopener">jupyter.org</a><br/> <b>Jupyter Desktop App</b>: <a href="https://ift.tt/3AN5J1J" target="_blank" rel="noopener">github.com</a><br/> <b>Jut</b>: <a href="https://ift.tt/3lwIjaP" target="_blank" rel="noopener">github.com</a><br/> <b>Jupyter project</b>: <a href="https://jupyter.org/" target="_blank" rel="noopener">jupyter.org</a><br/> <b>Watch this episode on YouTube</b>: <a href="https://www.youtube.com/watch?v=XAGmSPZsYLU" target="_blank" rel="noopener">youtube.com</a><br/> <b>Episode transcripts</b>: <a href="https://ift.tt/3pdyWyP" target="_blank" rel="noopener">talkpython.fm</a><br/> <br/> <b>--- Stay in touch with us ---</b><br/> <b>Subscribe on YouTube</b>: <a href="https://ift.tt/3DznvIg" target="_blank" rel="noopener">youtube.com</a><br/> <b>Follow Talk Python on Twitter</b>: <a href="https://twitter.com/talkpython" target="_blank" rel="noopener">@talkpython</a><br/> <b>Follow Michael on Twitter</b>: <a href="https://twitter.com/mkennedy" target="_blank" rel="noopener">@mkennedy</a><br/></div><br/> <strong>Sponsors</strong><br/> <a href='https://ift.tt/3k8IUjq> <a href='https://ift.tt/3aBjB2k> <a href='https://ift.tt/3vjihuL> <a href='https://ift.tt/2PVc9qH Python Training</a>
from Planet Python
via read more
Tuesday, November 30, 2021
PyCoder’s Weekly: Issue #501 (Nov. 30, 2021)
#501 – NOVEMBER 30, 2021
View in Browser »

Late-Bound Argument Defaults for Python
Python supports default values for arguments to functions, but those defaults are evaluated at function-definition time. A proposal to add defaults that are evaluated when the function is called has been discussed at some length on the python-ideas mailing list.
JAKE EDGE
Data Visualization Interfaces in Python With Dash
In this course, you’ll learn how to build a dashboard using Python and Dash. Dash is a framework for building data visualization interfaces. It helps data scientists build fully interactive web applications quickly.
REAL PYTHON course
Application Performance Monitoring Built for Developers, by Developers

Scout is a lightweight, production-grade application monitoring service built for modern development teams. Proactive alerting, real-time insight and always-on support means you can rest easy knowing Scout will find performance issues before your customers do. Embed our agent, and we’ll do the rest →
SCOUT APM sponsor
Rats in Doom: A Novel VR Setup for Rodents
A novel VR setup developed for rodents that lets rats play Doom. Uses Python for the controller interface.
VIKTOR TÓTH
CPython Dev in Residence: Weekly Report, November 22–28
A short review of try/except, exception handling in asyncio today, and the future of asyncio error handling.
ŁUKASZ LANGA
Discussions
Python Jobs
Senior Python Developer (Anywhere)
Senior Backend Engineer (Anywhere)
Senior Backend Software Engineer (Anywhere)
Senior Python Engineer (Anywhere)
Senior Software Engineer (United States)
Full Stack Software Engineer (Washington D.C., USA)
Senior Software Engineer (Washington D.C., USA)
Python Backend Engineer (Hasselt, Belgium)
Articles & Tutorials
Programmers Should Stop Celebrating Incompetence
The creator of Ruby on Rails on programmer competence: “The world has never had a greater need for programmers than it does today. It’s never had a greater need for competent programmers than it does today. Let’s skip the overly self-deprecating nonsense that nobody knows what they’re doing, and trying to learn things in depth is not for us.”
DAVD HEINEMEIER HANSSON opinion
How to Ditch Codecov for Python Projects
“Codecov’s unreliability breaking CI on my open source projects has been a constant source of frustration for me for years. I have found a way to enforce coverage over a whole GitHub Actions build matrix that doesn’t rely on third-party services.”
HYNEK SCHLAWACK
Get Your Next Python Job Through Hired

Hired is home to thousands of companies ranging from startups to Fortune 500s that are actively hiring developers, data scientists, mobile engineers, and more. Its really easy: once you create a profile, hiring managers can send interview requests based on your skills. Sign up today →
HIRED sponsor
Ready to Publish Your Python Packages?
Are you interested in sharing your Python project with the broader world? Would you like to make it easily installable using pip? How do you create Python packages that share your code in a scalable and maintainable way?
REAL PYTHON podcast
How to Write a Great Stack Overflow Question
“The single best thing you can do when asking for coding help online is provide a short, complete example script that others can copy, paste, and run without any modification to reproduce your problem.”
KEVIN MARKHAM • Shared by Kevin Markham
Experimental APIs in Python 3.10 and the Future of Trust Stores
“In Python 3.10.0 there were a few new APIs added to the ssl module related to certificate chains that weren’t listed in the Python 3.10 release notes due to being experimental.”
SETH MICHAEL LARSON
The Problem With Python’s map and filter (And How We Might Fix It)
The author explores the pros and cons of Python’s default map() and filter() implementation and potential improvements that could be made.
ABHINAV OMPRAKASH • Shared by Abhinav
Shortcut Provides Speedy Task Management, Reporting, and Collaboration for Software Teams
Shortcut is project management built for developers. Whether you’re a startup that iterates quickly by providing every engineer with a free pallet of Red Bull, or a large org that has strict ship dates to hit, give us a try for free.
SHORTCUT sponsor
The Rinds of the Cheese Shop Menu
A silly analysis of the weird and wonderful contents of PyPI: What are the longest package names? Numeric vs non-numeric version names?
BEN NUTTALL • Shared by Ben Nuttall
Projects & Code
RexMex: Recommender System Evaluation Library
GITHUB.COM/ASTRAZENECA • Shared by Benedek Rozemberczki
kolo: See Everything Happening in Your Running Django App
GITHUB.COM/KOLOFORDJANGO • Shared by Philipp Acsany
SQLLineage: SQL Lineage Analysis Tool
GITHUB.COM/REATA • Shared by Ryan Hu
FastAPI-Azure-Auth: Azure AD Auth for FastAPI Apps
INTILITY.GITHUB.IO • Shared by Jonas Krüger Svensson
Events
Weekly Real Python Office Hours Q&A (Virtual)
December 1, 2021
REALPYTHON.COM
FlaskCon 2021 Online
December 1 to December 5, 2021
FLASKCON.COM
PyCon Tanzania
December 1 to December 6, 2021
PYCON.OR.TZ
PyCode Conference
December 2 to December 4, 2021
PYCODE-CONFERENCE.ORG
Pyjamas Conf 2021
December 4 to December 6, 2021
PYJAMAS.LIVE
PyCon Indonesia 2021
December 4 to December 6, 2021
PYCON.ID
Happy Pythoning!
This was PyCoder’s Weekly Issue #501.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
from Planet Python
via read more
STX Next: Python Outsourcing: A Short Guide for CTOs and Technical Managers

If we could distill Python’s main advantage over other programming languages into just one word, it would be: “simplicity.”
from Planet Python
via read more
Ching-Hwa Yu: How to Create a Python Plugin System with Stevedore
 Photo by Kieran Wood on Unsplash
Photo by Kieran Wood on Unsplash
One of the questions that I see and hear often is how to extend applications using a Python plugin system. For a test engineer, this is usually related to hardware abstraction. For others, they may want to separate the core functionality from extensions. Through this method, deployment can be simplified where only the required pieces are installed through their individual package(s). Whatever the reason may be, several libraries are available to tackle this challenge. In this article, a simple abstraction layer will be built using the Stevedore library and we will cover the the main concepts of building plugins.
The code in this article is available at https://github.com/chinghwayu/plugin_tutorial.
NOTE: While the code illustrates relays and a hardware abstraction layer, the same concept can be used for services such as a database with a software abstraction layer.
Plugin Architecture
Regardless of the plugin framework used, the architecture behind the implementation of plugins is mostly the same.
- Define abstract base class
- Define plugin class inheriting from base class
Abstract Base Class
For plugins of similar type in a Python plugin system, there usually is some common functionality. Plugins based on a protocol or specification typically have common basic functionality. For example, instruments that adhere to IEEE 488.2 standard must respond to queries for its identification.
Although the abstract part is sometimes omitted, this is an important step as it establishes the basic structure of each plugin by defining which methods must be implemented. In Python, this is accomplished with the abc module.
The example shown defines a basic relay instrument driver with three methods – connect, disconnect, and reconnect. In the __init__ method, the connected attribute is established for status as this is common between all plugins.
For the other abstract methods, only docstrings are needed. There is no need to include pass or other code.
from abc import ABCMeta, abstractmethod
class RelayBase(metaclass=ABCMeta):
"""Base class for relay plugins"""
def __init__(self) -> None:
"""Define base attributes."""
self.connected = False
@abstractmethod
def disconnect(self) -> None:
"""Disconnects relay."""
@abstractmethod
def connect(self) -> None:
"""Connects relay."""
@abstractmethod
def reconnect(self, seconds: int) -> None:
"""Disconnects for specified time and reconnects.
Args:
seconds (int): Amount of time to sleep between disconnect and connect.
"""
Plugin Class
When defining the actual implementation, each of the plugins will inherit from the plugin base class. In the example, two plugins are defined that inherit from RelayBase.
In the __init__ method, a super() call is made to create the connected attribute which the other methods will update.
class RelayOne(RelayBase):
def __init__(self):
super().__init__()
def disconnect(self):
self.connected = False
print("Disconnected One")
def connect(self):
self.connected = True
print("Connected One")
def reconnect(self, seconds: int = 5):
self.seconds = seconds
self.disconnect()
print(f"One paused for {seconds} seconds...")
self.connect()
class RelayTwo(RelayBase):
def __init__(self):
super().__init__()
def disconnect(self):
self.connected = False
print("Disconnected Two")
def connect(self):
self.connected = True
print("Connected Two")
def reconnect(self, seconds: int = 5):
self.seconds = seconds
self.disconnect()
print(f"Two paused for {seconds} seconds...")
self.connect()
Loading Plugins
At this point, you may think that this is all that’s needed to establish a Python plugin system. For simple plugins, this may be true. However, consider the following:
- How do we decide which plugin to call at runtime?
- How can we easily switch between the implementations?
- How can we package these plugins for distribution?
- How can we test the interfaces to ensure the correct implementation is being called?
For simple applications or scripts, we may simply call the specific implementation directly and hardcode this in. But consider the case where you may be sharing code with a teammate in another location and they don’t have the same relay. We don’t want to maintain another version of the same code with the alternate implementation hardcoded. What we need is way to easily switch between implementations without altering any code. The only change that should be made is in a configuration file for which implementation to use at runtime.
Plugin Entry Point
There are several ways to discover and load plugins. With Stevedore, this uses entry points to establish keys that can be queried as pointers to the location of specific code. This is the same mechanism found often in packages that enable the launching of Python code as command line scripts once installed into an environment. While this uses a built in console_scripts type of entry point, custom entry point types can be created for the purpose of managing plugins.
For a full discussion on extending applications with plugins, please watch the PyCon 2013 talk on this subject from the author of Stevedore, Doug Hellman. The presentation compares the approach taken with Stevedore compared to other existing approaches at the time.
When building packages for distribution, we can add entry points so that when it’s installed into a Python environment, the environment immediately knows where the plugins are located from the established keys. Adding entry points is simple. In the setup.py for a package, assign a dictionary to the entry_points parameter of setup.
from setuptools import setup
setup(
entry_points={
"plugin_tutorial": [
"relay1 = relay:RelayOne",
"relay2 = relay:RelayTwo",
],
},
)
The plugin_tutorial key is used as the plugin namespace. The names for each plugin is defined as relay1 and relay2. The location of the the plugin is defined as the module name and class within the module separated by colon, relay:RelayOne and relay:RelayTwo.
For cases when we are using plugins but don’t need to install as package, we can register them into the entry point cache of Stevedore. This is useful for development purposes and when implementing unit tests.
The example below checks a namespace for the specified entry point. If the entry point doesn’t exist, it will be added.
View this gist on GitHubRegisters a stevedore plugin dynamically without needing to install as a package
Managing Plugins
With Stevedore, there are several ways to manage plugins in a Python plugin system.
- Drivers – Single Name, Single Entry Point
- Hooks – Single Name, Many Entry Points
- Extensions – Many Names, Many Entry Points
For this article, the driver approach will be discussed since that is the most common use case. Take a look at the Stevedore documentation that discuss Patterns for Loading for the other methods.
For a driver, we need to call the DriverManager. In the parameter list, only namespace and name are required which are directly related to the entry points. Optional parameters are available and the one used in this example is invoke_on_load. While the relay example only establishes a class attribute, for an actual instrument driver, we usually need to perform some kind of initialization. This can be executed at the time when the plugin is loaded.
Calling DriverManager will return a manager object. The actual driver object can be accessed through the driver property. From this property, we can also create abstracted methods to call the driver methods.
from stevedore import driver
class Relay:
def __init__(self, name="", **kwargs) -> None:
self._relay_mgr = driver.DriverManager(
namespace="plugin_tutorial",
name=name,
invoke_on_load=True,
invoke_kwds=kwargs,
)
@property
def driver(self):
return self._relay_mgr.driver
def disconnect(self) -> None:
self.driver.disconnect()
def connect(self) -> None:
self.driver.connect()
def reconnect(self, seconds: int = 5) -> None:
self.driver.reconnect(seconds)
The **kwargs parameter is not used but included to show implementation of how to pass parameters to drivers which may have different initialization parameters.
The @property decorator for the driver method is syntactic sugar to provide a shortcut to the driver object. If this wasn’t provided, we would need to call the driver’s disconnect method as:
r = Relay(name="relay1")
r._relay_mgr.driver.disconnect()
Putting It Together
For a plugin installed into a Python environment, the entry points have established when the package was installed. Through the abstraction interface, we can decide which plugin to load at runtime. Shown is a unit test that calls both plugins and each of its methods.
In order to run this, we will need to first install as a package.
$ pip install -e /path/to/plugin_tutorial
...
Installing collected packages: plugin-tutorial
Running setup.py develop for plugin-tutorial
Successfully installed plugin-tutorial
$ pip list | grep plugin_tutorial
plugin-tutorial 1.0.0 /path/to/plugin_tutorial
from relay import Relay
def test_installed_plugin():
r1 = Relay(name="relay1")
assert isinstance(r1, Relay)
assert r1.driver.connected == False
r1.disconnect()
assert r1.driver.connected == False
r1.connect()
assert r1.driver.connected == True
r1.reconnect(7)
assert r1.driver.seconds == 7
r2 = Relay(name="relay2")
assert isinstance(r2, Relay)
assert r2.driver.connected == False
r2.disconnect()
assert r2.driver.connected == False
r2.connect()
assert r2.driver.connected == True
r2.reconnect(9)
assert r2.driver.seconds == 9
To call plugins not installed through the package installation process, we’ll need to first register and then call the plugins. This is useful for writing unit tests that include a dummy plugin. Shown is the same unit test with the plugin registered.
from relay import Relay
from register_plugin import register_plugin
def test_register_plugin():
namespace = "plugin_tutorial"
register_plugin(
name="relay1",
namespace=namespace,
entry_point="relay:RelayOne",
)
register_plugin(
name="relay2",
namespace=namespace,
entry_point="relay:RelayTwo",
)
r1 = Relay(name="relay1")
assert isinstance(r1, Relay)
assert r1.driver.connected == False
r1.disconnect()
assert r1.driver.connected == False
r1.connect()
assert r1.driver.connected == True
r1.reconnect(7)
assert r1.driver.seconds == 7
r2 = Relay(name="relay2")
assert isinstance(r2, Relay)
assert r2.driver.connected == False
r2.disconnect()
assert r2.driver.connected == False
r2.connect()
assert r2.driver.connected == True
r2.reconnect(9)
assert r2.driver.seconds == 9
Resources
For additional information:
- Tutorial code – https://github.com/chinghwayu/plugin_tutorial
- stevedore user guide – https://docs.openstack.org/stevedore/latest/user/index.html
- Abstract Base Classes – https://docs.python.org/3/library/abc.html
- Entry points – https://docs.python.org/3/library/importlib.metadata.html#entry-points
- PyCon 2013 presentation on stevedore – https://youtu.be/7K72DPDOhWo
- Yapsy (Yet Another Plugin System) – http://yapsy.sourceforge.net/
- Pluggy (Pytest plugin systest) – https://pluggy.readthedocs.io/en/stable/
The post How to Create a Python Plugin System with Stevedore appeared first on Ching-Hwa Yu.
from Planet Python
via read more
Python for Beginners: Shortest Path Length from a Vertex to other Vertices in a Graph
Graphs are used to represent geographical maps, computer networks, etc. In this article, we will discuss how to calculate the shortest distance between vertices in an unweighted graph. To calculate the shortest path length from a vertex to other vertices, we will use breadth first search algorithm.
How to calculate the Shortest Path Length from a Vertex to other vertices?
In an unweighted graph, all the edges have equal weight. It means that we just have to count the number of edges between each vertex to calculate the shortest path length between them.
For example, consider the following graph.
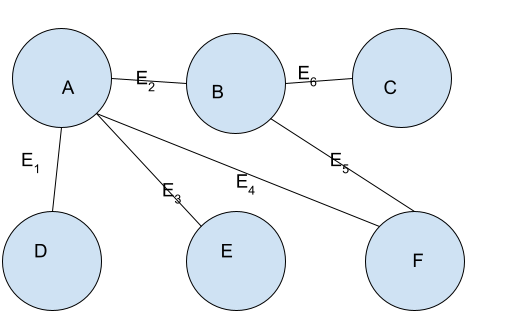 Graph in Python
Graph in Python
Let us calculate the shortest distance between each vertex in the above graph.
There is only one edge E2 between vertex A and vertex B. So, the shortest path length between them is 1.
We can reach C from A in two ways. The first one is using the edges E4-> E5->E6 and the second path is using the edges E2-> E6. Here, we will choose the shortest path, i.e. E2-> E6. Hence the shortest path length between vertex A and vertex C is 2.
There is only one edge E1 between vertex A and vertex D. So, the shortest path length between them is 1.
There is only one edge E3 between vertex A and vertex E. So, the shortest path length between them is 1.
We can reach F from A in two ways. The first one is using the edges E2-> E5 and the second path is using the edges E4. Here, we will choose the shortest path, i.e. E4. Hence the shortest path length between vertex A and vertex F is 1.
Algorithm to calculate the Shortest Path Length from a Vertex to other vertices
By now, you must have understood that we have to count the number of edges between the vertices to calculate the distance between the vertices. For this, we will modify the breadth first search algorithm as follows.
- We will declare a python dictionary that will contain the vertices as their keys and distance from the source vertex as the associated values.
- Initially, we will assign the distance of each vertex from the source as infinite , denoted by a large number. Whenever we will find a vertex during traversal, we will calculate the current distance of the vertex from the source. If the current distance appears to be less than the distance mentioned in the dictionary containing the distance between source and other vertices, we will update the distance in the dictionary.
- After full breadth first traversal, we will have the dictionary containing the least distance from the source to each vertex.
We can formulate the algorithm for calculating the shortest path length between vertices of an unweighted graph as follows.
- Create an empty Queue Q.
- Create a list visited_vertices to keep track of visited vertices.
- Create a dictionary distance_dict to keep track of distance of vertices from the source vertex. Initialize the distances to 99999999.
- Insert source vertex into Q and visited_vertices.
- If Q is empty, return. Else goto 6.
- Take out a vertex v from Q.
- Update the distances of unvisited neighbors of v in distance_dict.
- Insert the unvisited neighbors to Q and visited_vertices.
- Go to 5.
Implementation
As we have discussed the example and formulated an algorithm to find the shortest path length between source vertex and other vertices in a graph, let us implement the algorithm in python.
from queue import Queue
graph = {'A': ['B', 'D', 'E', 'F'], 'D': ['A'], 'B': ['A', 'F', 'C'], 'F': ['B', 'A'], 'C': ['B'], 'E': ['A']}
print("Given Graph is:")
print(graph)
def calculate_distance(input_graph, source):
Q = Queue()
distance_dict = {k: 999999999 for k in input_graph.keys()}
visited_vertices = list()
Q.put(source)
visited_vertices.append(source)
while not Q.empty():
vertex = Q.get()
if vertex == source:
distance_dict[vertex] = 0
for u in input_graph[vertex]:
if u not in visited_vertices:
# update the distance
if distance_dict[u] > distance_dict[vertex] + 1:
distance_dict[u] = distance_dict[vertex] + 1
Q.put(u)
visited_vertices.append(u)
return distance_dict
distances = calculate_distance(graph, "A")
for vertex in distances:
print("Shortest Path Length to {} from {} is {}.".format(vertex, "A", distances[vertex]))
Output:
Given Graph is:
{'A': ['B', 'D', 'E', 'F'], 'D': ['A'], 'B': ['A', 'F', 'C'], 'F': ['B', 'A'], 'C': ['B'], 'E': ['A']}
Shortest Path Length to A from A is 0.
Shortest Path Length to D from A is 1.
Shortest Path Length to B from A is 1.
Shortest Path Length to C from A is 2.
Shortest Path Length to E from A is 1.Conclusion
In this article, we have discussed and implemented the algorithm to calculate the shortest path length between vertices in an unweighted graph. Here we have used the breadth first graph traversal algorithm. To read about binary tree traversal algorithms, you can read Inorder tree traversal algorithm or level order tree traversal algorithm.
The post Shortest Path Length from a Vertex to other Vertices in a Graph appeared first on PythonForBeginners.com.
from Planet Python
via read more
XGBoost vs LightGBM: How Are They Different
Gradient Boosted Machines and their variants offered by multiple communities have gained a lot of traction in recent years. This has been primarily due to the improvement in performance offered by decision trees as compared to other machine learning algorithms both in products and machine learning competitions. Two of the most popular algorithms that are […]
The post XGBoost vs LightGBM: How Are They Different appeared first on neptune.ai.
from Planet SciPy
read more
PyCharm: Last day to buy PyCharm and Support Python!

You still have 1 day to purchase your PyCharm Pro license at 30% off and have the full amount of your purchase donated directly to the PSF!
Buy PyCharm and Support Python
PyCharm joins the Python Software Foundation on their end-of-the-year fundraiser one more time! Since November 9 you can purchase a new PyCharm Pro individual license at 30% off, and have the full amount of your purchase donated directly to the PSF.
The campaign ends tomorrow, December 1. If you still want to support Python, the time is now!
About the Partnership
The Python Software Foundation is the principal organization behind the Python programming language. As a non-profit organization, the PSF depends on sponsorships and donations to support its work. The contributions are used to maintain ongoing sprints, meetups, community events, Python documentation, fiscal sponsorships, software development, and community projects. None of this is possible without your support.
The end-of-the-year fundraiser is an important source of resources for the PSF and helps sustain programs that support the larger Python community. The Python Software Foundation and JetBrains have partnered before, conducting four consecutive Python Developers Surveys, and this year JetBrains PyCharm will once again support the Python Software Foundation in its fundraiser campaign.
from Planet Python
via read more
Real Python: Data Visualization Interfaces in Python With Dash
In the past, creating analytical web applications was a task for seasoned developers that required knowledge of multiple programming languages and frameworks. That’s no longer the case. Nowadays, you can make data visualization interfaces using pure Python. One popular tool for this is Dash.
Dash gives data scientists the ability to showcase their results in interactive web applications. You don’t need to be an expert in web development. In an afternoon, you can build and deploy a Dash app to share with others.
In this course, you’ll learn how to:
- Create a Dash application
- Use Dash core components and HTML components
- Customize the style of your Dash application
- Use callbacks to build interactive applications
- Deploy your application on Heroku
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
from Planet Python
via read more
Data Visualization Interfaces in Python With Dash
In the past, creating analytical web applications was a task for seasoned developers that required knowledge of multiple programming languages and frameworks. That’s no longer the case. Nowadays, you can make data visualization interfaces using pure Python. One popular tool for this is Dash.
Dash gives data scientists the ability to showcase their results in interactive web applications. You don’t need to be an expert in web development. In an afternoon, you can build and deploy a Dash app to share with others.
In this course, you’ll learn how to:
- Create a Dash application
- Use Dash core components and HTML components
- Customize the style of your Dash application
- Use callbacks to build interactive applications
- Deploy your application on Heroku
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
from Real Python
read more
Test and Code: 172: Designing Better Software with a Prototype Mindset
A prototype is a a preliminary model of something, from which other forms are developed or copied.
In software, we think of prototypes as early things, or a proof of concept.
We don't often think of prototyping during daily software development or maintenance. I think we should.
This episode is about growing better designed software with the help of a prototype mindset.
Sponsored By:
- PyCharm Professional: Try PyCharm Pro for 4 months and learn how PyCharm will save you time. Promo Code: TESTANDCODE22
Links:
- Selecting a programming language can be a form of premature optimization — Brett Cannon's blog post
from Planet Python
via read more
Monday, November 29, 2021
Matthew Wright: Financial market data analysis with pandas
Pandas is a great tool for time series analysis of financial market data. Because pandas DataFrames and Series work well with a date/time based index, they can be used effectively to analyze historical data. By financial market data, I mean data like historical price information on a publicly traded financial instrument. However, any sort of … Continue reading Financial market data analysis with pandas
The post Financial market data analysis with pandas appeared first on wrighters.io.
from Planet Python
via read more
TestDriven.io: Reproducible Builds with Bazel
This article looks at how Bazel can be used to create reproducible, hermetic builds.
from Planet Python
via read more
from Planet Python
via read more
TestDriven.io: Dynamic Secret Generation with Vault and Flask
In this tutorial, we'll look at a real-world example of using Hashicorp's Vault and Consul to create dynamic Postgres credentials for a Flask web app.
from Planet Python
via read more
from Planet Python
via read more
Łukasz Langa: Weekly Report, November 22 - 28
Python⇒Speed: Is it worth the money? When to buy products for your job
You’ve discovered a product that might help you with your job: perhaps a book that will teach you a new and relevant skill, or software that will speed up development. Since you do want to write software better and faster, you are considering buying this product. But, then again, the product costs money, and maybe that money is better spent on something else.
So should you buy the product or not?
How do you decide?
If it is worth buying, how can you convince your boss to approve the purchase?
While it’s impossible to know with certainty, a few simple heuristics can make the decision much easier. Which heuristic to use depends on your situation, of course. So this article will cover:
- Buying products with your employer’s money: the “hours-saved” heuristic.
- Buying products on your own, and why you should usually restrict this to educational products.
- Some concrete examples to make this all clearer.
- Saving money, including when you live in a low-income country.
from Planet Python
via read more
Mike Driscoll: PyDev of the Week: Pradyun Gedam
This week we welcome Pradyun Gedam (@pradyunsg) as our PyDev of the Week! Pradyun works on pip, Python Packaging Index (PyPI), the Python Packaging Authority (PyPA), Sphinx, TOML and more! Pradyun blogs and does talks. You can find out more about those on his website. If you're more interested in seeing Pradyun's work, then you ought to head on over to GitHub or GitLab.
Let's spend a few moments getting to know Pradyun better!
Can you tell us a little about yourself (hobbies, education, etc.)?
I grew up in Mumbai, but recently moved to the UK, where I’m working for Bloomberg. I’m part of the company’s Python Infrastructure team, mainly focusing on the software infrastructure and developer experience for Python within the organization.
I generally like sports. I’ve played a lot of cricket, basketball, and football throughout most of my life. Unfortunately, I haven’t been able to play any of those team sports recreationally for over a year now.
However, I have played a lot of video games lately. I have a strong bias toward systemic simulation games. Rimworld has been slurping up a lot of my free time over the past few weeks – perhaps, to the point of being unhealthy, now that I think about it. In the recent past, Steam tells me I’ve been playing Parkitect, Dyson Sphere Program, Oxygen Not Included, Hitman 2, and Rocket League.
I feel like I’m a weird breed of video gamer though – my last two gaming systems have been a Linux Desktop and a MacBook Air. My only Windows-based gaming happens through my GeForce NOW subscription.
Education-wise, I have a bachelor’s degree in “Computer Science Engineering.”
Why did you start using Python?
To make my own video game! Python was the first programming language I learnt, and I learnt it to make games.
I was in 8th grade, if I remember correctly, when my parents gave me the book “Core Python Programming” with the suggestion: How about you learn how to make games instead of just playing them?
That was a very sticky idea. So, after putting it off for a while, I did indeed pick up the book and learnt from it. By the end of it, I had learnt a lot about computers in general, and then went on to build a 2-player 2D tank shooter as well!
I found the process of writing my own game more fun than actually playing it, so I started looking around for more things to make with this new skill I had learnt.
What other programming languages do you know, and which is your favorite?
I definitely spend a lot of my time working with Python, largely biased by the fact that it’s the one I’m most familiar with. That is followed by web technologies (JavaScript, CSS, HTML). I also work a decent amount with C++ code at work. I’ve enjoyed working with Rust at every opportunity/excuse I’ve had to do so; especially since the entire development experience and tooling around the language are great. I’ve also attended beginner sessions for Clojure, Ruby, and Haskell in the past, but I won’t say I know them.
To be honest, I don’t think I have any favorites here – to me, programming languages are tools in the toolbox of a software engineer. The tools I’m most familiar with are Python, web technologies (JS, CSS, HTML, and their various relatives), C++, and Rust.
What projects are you working on now?
Lately, it’s been a mix of working on Python Packaging tooling, Sphinx documentation stuff, and fiddling around with speech recognition on my Raspberry Pi.
I ended up updating the page on my website about what I’m working on while writing my response here, so I guess that’s the rest of my answer. 
Which Python libraries are your favorite (core or third-party)?
The most fun I’ve had with Python has been with the ast module – mostly because it led to me learn way more than I needed to about language grammars, parsers, parser generators, and language design.
PursuedPyBear (ppb) is an educational game engine and the project that I’m most excited to see growing. Video games is how I got started with Python, and ppb provides a much better foundation for learning Python (and game development) than what I had!
rich is also high up on the list of packages that I like right now!
How did you get started with the Python Packaging Authority (PyPA)?
Honestly, I feel like I stumbled my way into it.
That was purely curiosity driven for me – “oh, GitHub is a thing” ? “oh, I can read source code of things I use” ? “oh, the people who wrote this have discussions in this issues tab”. So… I ended up reading on some of the long-standing issues on the project. And then, making comments in those issues and summarizing the discussions so far. Something I didn’t realise back then: When you write a summary of a really long GitHub discussion, you also retrigger the whole discussion based on that summary.
The first major discussion I got involved in like this was about how pip install --upgrade <something> behaves, which quickly got entangled with how pip install <directory> should reinstall the project from the directory. It just spiraled from there.
This was around May or June 2016. At this point, I had been writing Python code for fun for about two or three years. It was just after I’ve given my final exams for high school (12th grade). Given that I wasn’t exactly preparing for “Joint Entrance Examination” (JEE) full time – unlike most of my peers – I had a bunch of free time on my hands.
So, I ended up putting that time into what ended up being a few months of technical discussion about what-do-we-do-here. The whole thing resulted in a +163 ?13 PR at the end – and I learnt very quickly that a lot of working on software is a people thing.
I actually enjoyed the process and learnt a lot of new things as a result. There was a certain dopamine rush associated with that the whole thing, so I ended up spending more time on the project. A few months later, I got into a college and realised that I can apply for Google Summer of Code (GSoC)! I did that in 2017, and a couple of months after that was over, I got offered the commit bit on pip and virtualenv.
Since then, I’ve been involved in some form with nearly every PyPA project on GitHub – either as a direct code contributor, engaging in discussions on their issue tracker, or as someone providing inputs in the standardisation process.
And, since I looked these up while writing this: My first commit in pip was updating a bunch of http URLs to https.
e04941bba Update http urls to use https instead (#3808)
What have you been doing with Sphinx lately?
Actually, quite a lot, now that this question has made me think about it.
Documentation is a big part of software’s usability story, and a large part of how users interact with a given project. I’ve always felt that Sphinx-based documentation looked very dated, thereby contributing to lower quality content and a poor user experience. These feelings were validated and boosted by the user experience research that was conducted for pip throughout 2020.
Long story short, I ended up writing a Sphinx theme (Furo) that’s become quite popular (if I may say so myself). In the process of writing that theme, I discovered a bunch more things I could do. So… since then, I have:
- worked with the original author of sphinx-themes.org and completely revamped the website (twice!), while also making it significantly easier to maintain.
- picked up the maintenance of sphinx-autobuild, which provides a really nice live-reloading experience for writing Sphinx documentation.
- collaborated with various folks from ReadTheDocs to improve things around Sphinx on their platform.
- gotten involved in conversations about Sphinx, both in the issue tracker of Sphinx, as well as in the technical writing spaces (like Write The Docs).
- become a member of the Executable Books Project, where I’m trying to help out with all the cool things that everyone else is building.
- started writing a second theme and a bunch of theme-related tooling for Sphinx (though, I’ve not posted the code publicly yet).
The first public beta of Furo was 2020.9.2.beta1, which was over a year ago!
Of the packages that you help maintain, what’s your favorite and why?
Hmm… this is a tricky question to answer. It doesn’t help that I genuinely have so many things to choose from.
Furo comes to mind first. It is probably the only project I work on where I make the final call on everything unilaterally. It helps that it looks pretty and that it’s visible when someone uses it.
However, the project I spend the most time on is definitely pip. That is not the most fun project to work on though, even though it can be the most rewarding in terms of the sheer number of users I can help through my involvement with it.
What are the biggest challenges that the PyPA is facing?
Oh wow, that’s a heavy question. There’s a lot to unpack here.
I think one of the unique things about Python’s packaging tooling, compared to most other popular languages, is that it’s almost entirely driven by volunteers. This contrasts drastically with the investments and resources that other ecosystems have put toward their tooling. There are many consequences of this, but this question is about the challenges, so I’ll stick to those aspects.
There are definitely a lot of known functionality improvements that are difficult to get done with only volunteers. It is often tricky to coordinate across projects since availability is a hit-or-miss story. Improvements take time and generally progress slowly, both due to the volunteer nature of the labour, as well as the scope and scale of the work. Broadly, the PyPA operates on consensus and that is often not straightforward to establish. Even in those cases where we all agree and know exactly what needs to be done, we simply don’t have the ability to “throw” developer time at it to solve it.
There’s also the problem of poor documentation and communication channels. As with the functionality improvements, there’s limited availability of folks with the right skills and knowledge to invest the necessary energy into these areas. This isn’t helped by the fact that these areas are fairly complicated and nuanced in their own right, often rivaling the code changes in the amount of energy and understanding necessary to get things right.
Paying down our accrued technical debt doesn’t really attract as much energy as it should IMO, especially for something so foundational to the Python language ecosystem. A lot of improvements are blocked on this, since many foundational projects have a whole lot of technical debt which hasn’t been paid down. This sort of long-term low-effort/low-reward stuff is difficult to do when everyone’s a volunteer. Some things are easier when you’re getting paid to do it. Paying down technical debt is certainly one of these. Conversely, paying down technical debt is also tricky to get funding for on its own. 🙂
The “shackles” of backwards compatibility is another challenge (I consider this distinct from technical debt). There are many behaviours, CLI options, API designs, names for parameters/functions, etc. that people rely on in these tools. We’ve also learnt that some of these are confusing, frustrating, poorly named, and overall horrible for the user experience. Or, they are sub-optimal choices/names/approaches, especially given that we have the context we do today. Or, there’s a better approach for solving these issues, since we’ve made improvements in other parts of the ecosystem. But we can’t do much about them anytime soon, since we can’t break the parts of the Python ecosystem that depend on these behaviours.
All of this isn’t news to the folks who are actively involved in this space, or to many of your readers. Some of these are constraints that any long-standing software system has. That said, there has been substantial effort put toward improving this ecosystem as a whole over the last few years!
The PyPA’s standards-based approach is starting to show its benefits, through the ecosystem of alternatives to setuptools and overall workflow tooling that has been built over the last few years – these don’t have the same technical debt or backwards compatibility concerns and can innovate at a much faster pace. There are also multiple efforts underway to create re-usable libraries that implement functionality that, earlier, was only available within the internals of long-standing tools (e.g., pip, setuptools, distutils, etc.).
The Python Software Foundation’s Packaging Working Group (Packaging-WG) has been working toward securing funding for the Python ecosystem. They actually maintain a list of fundable Python Packaging improvements which are well-scoped, have clear consensus among the community, and are clearly going to improve an end-users’ experience – all of which are things that organisations that could fund this kind of work would want.
The Packaging-WG’s efforts have been very fruitful, leading to some very visible and impactful work being funded, like the new pypi.org site and the pip resolver rewrite (I worked on this one!). These were the sorts of things that would’ve taken many more years had they been undertaken only by volunteers and we hadn’t gotten this sort of funding. This has also led to establishing better documentation and communication around changes, including setting up “infrastructure” for doing a better job on these fronts going forward.
Thanks so much for doing the interview, Pradyun!
The post PyDev of the Week: Pradyun Gedam appeared first on Mouse Vs Python.
from Planet Python
via read more
Sunday, November 28, 2021
Stack Abuse: Graphs in Python: Breadth-First Search (BFS) Algorithm
Introduction
Graphs are one of the most useful data structures. They can be used to model practically everything - object relations and networks being the most common ones. An image can be represented as a grid-like graph of pixels, and sentences can be represented as graphs of words. Graphs are used in various fields, from cartography to social psychology even, and of course they are widely used in Computer Science.
Due to their widespread use, graph search and traversal play an important computational role. The two fundamental algorithms used for graph search and traversal are Depth-First Search (DFS) and Breadth-First Search (BFS).
If you'd like to read more about Depth-First Search, read our Graphs in Python: Depth-First Search (DFS) Algorithm!
In this article we will go over the theory behind the algorithm and the Python implementation of Breadth-First Search and Traversal. First, we'll be focusing on node search, before delving into graph traversal using the BFS algorithm, as the two main tasks you can employ it for.
Note: We're assuming an adjacency-list implemented graph in the guide.
Breadth-First Search - Theory
Breadth-First Search (BFS) traverses the graph systematically, level by level, forming a BFS tree along the way.
If we start our search from node v (the root node of our graph or tree data structure), the BFS algorithm will first visit all the neighbours of node v (it's child nodes, on level one), in the order that is given in the adjacency list. Next, it takes the child nodes of those neighbours (level two) into consideration , and so on.
This algorithm can be used for both graph traversal and search. When searching for a node that satisfies a certain condition (target node), the path with the shortest distance from the starting node to the target node. The distance is defined as the number of branches traversed.
Breadth-First Search can be used to solve many problems such as finding the shortest path between two nodes, determining the levels of each node, and even solving puzzle games and mazes.
While it's not the most efficient algorithm for solving large mazes and puzzles - and it's outshined by algorithms such as Dijkstra's Algorithm and A* - it still plays an important role in the bunch and depending on the problem at hand - DFS and BFS can outperform their heuristic cousins.
If you'd like to read more about Dijkstra's Algorithm or A* - read our Graphs in Python: Dijkstra's Algorithm and Graphs in Python: A* Search Algorithm!
Breadth-First Search - Algorithm
When implementing BFS, we usually use a FIFO structure like a Queue to store nodes that will be visited next.
Note: To use a Queue in Python, we need to import the corresponding Queue class from the queue module.
We need to pay attention to not fall into infinity loops by revisiting the same nodes over and over, which can easily happen with graphs that have cycles. Having that in mind, we'll be keeping track of the nodes that have been visited. That information doesn't have to be explicitly saved, we can simply keep track of the parent nodes, so we don't accidentally go back to one after it's been visited.
To sum up the logic, the BFS Algorithm steps look like this:
- Add the root/start node to the
Queue. - For every node, set that they don't have a defined parent node.
- Until the
Queueis empty:- Extract the node from the beginning of the
Queue. - Perform output processing.
- For every neighbour of the current node that doesn't have a defined parent (is not visited), add it to the
Queue, and set the current node as their parent.
- Extract the node from the beginning of the
Output processing is performed depending on the purpose behind the graph search. When searching for a target node, output processing is usually testing if the current node is equal to the target node. This is the step on which you can get creative!
Breadth-First Search Implementation - Target Node Search
Let's first start out with search - and search for a target node. Besides the target node, we'll need a start node as well. The expected output is a path that leads us from the start node to the target node.
With those in mind, and taking the steps of the algorithm into account, we can implement it:
from queue import Queue
def BFS(adj_list, start_node, target_node):
# Set of visited nodes to prevent loops
visited = set()
queue = Queue()
# Add the start_node to the queue and visited list
queue.put(start_node)
visited.add(start_node)
# start_node has not parents
parent = dict()
parent[start_node] = None
# Perform step 3
path_found = False
while not queue.empty():
current_node = queue.get()
if current_node == target_node:
path_found = True
break
for next_node in adj_list[current_node]:
if next_node not in visited:
queue.put(next_node)
parent[next_node] = current_node
visited.add(next_node)
# Path reconstruction
path = []
if path_found:
path.append(target_node)
while parent[target_node] is not None:
path.append(parent[target_node])
target_node = parent[target_node]
path.reverse()
return path
When we're reconstructing the path (if it is found), we're going backwards from the target node, through it's parents, retracing all the way to the start node. Additionally, we might want to reverse the path for our own intuition of going from the start_node towards the target_node.
On the other hand, if there is no path, the algorithm will return an empty list.
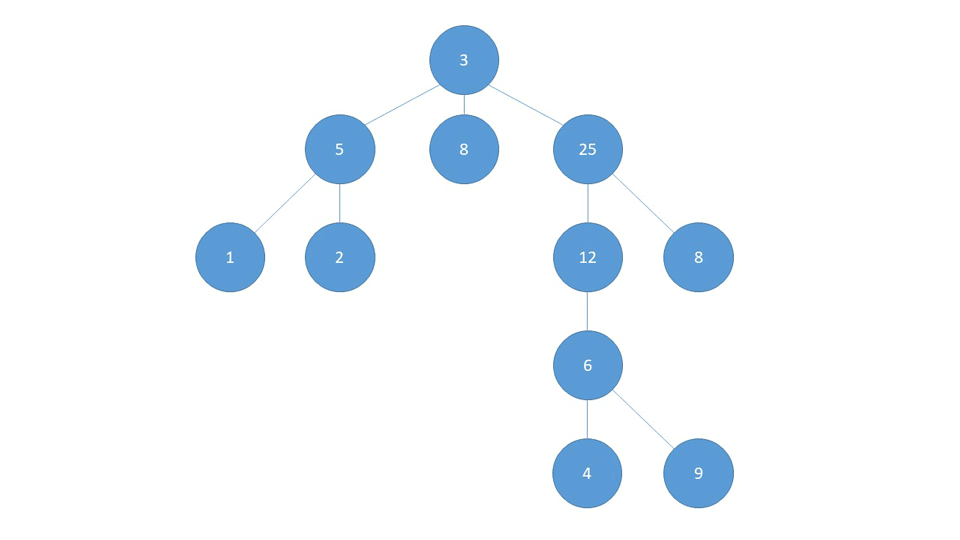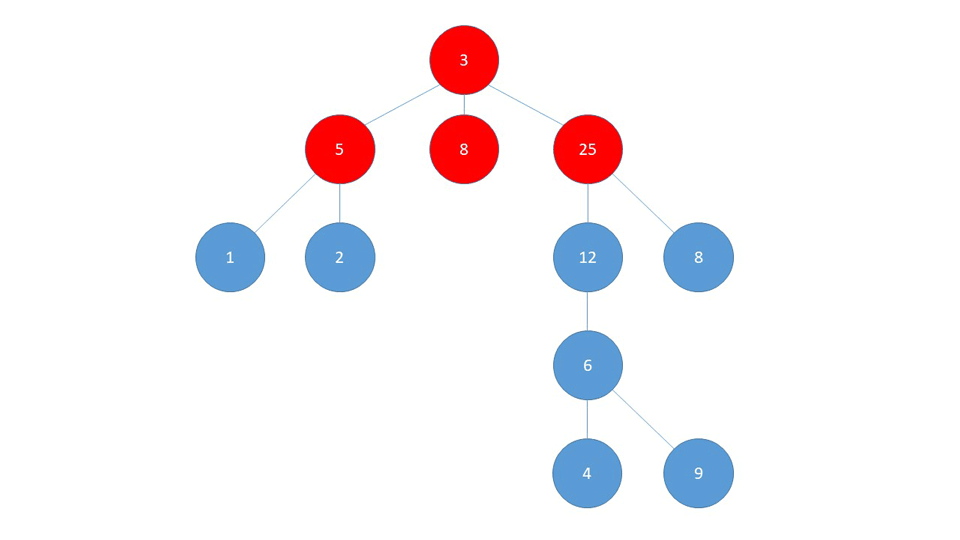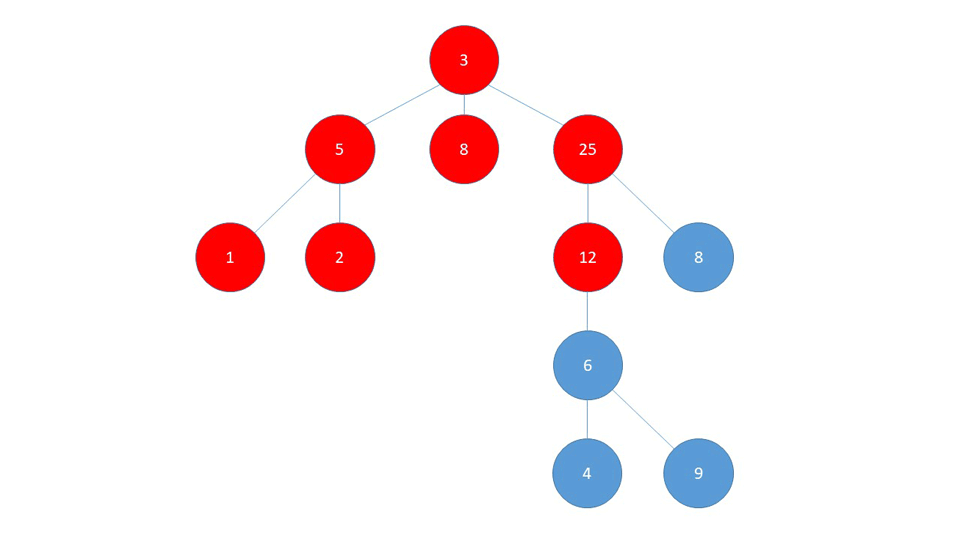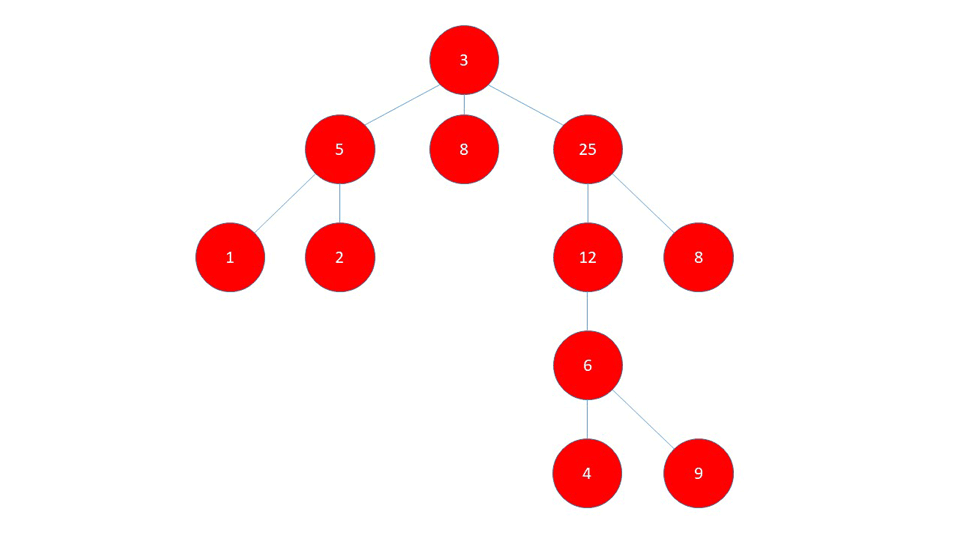
Let's construct a simple graph, as an adjacency list:
graph = {
1 : [2, 3, 4, 5],
2 : [1, 3],
3 : [1, 2, 4, 6],
4 : [1, 3, 5, 6],
5 : [1, 4, 6],
6 : [3, 4, 5]
}
Now, say we'd like to search for node 6 starting at node 1:
path = BFS(graph, 1, 6)
print(path)
Running this code results in:
[1, 3, 6]
Now, let's take a look at a visual representation of the graph itself:

The shortest path between 1 and 6 is indeed [1, 3, 6]. Though, you could also traverse [1, 4, 6] which appears to be shorter (due to a diagonal path), and [1, 5, 6]. These alternative paths are, fundementally, the same distance as [1, 3, 6] - however, consider how BFS compares nodes. It "scans" from left to right and 3 is the first node on the left-hand side of the adjacency list that leads to 6, so this path is taken instead of the others.
Note: There are cases in which a path between two nodes cannot be found. This scenario is typical for disconnected graphs, where there are at least two nodes that are not connected by a path.
Here's how a disconected graph looks like:

If we were to try and perform a search for a path between nodes 0 and 3 in this graph, that search would be unsuccessful, and an empty path would be returned.
Breadth-First Implementation - Graph Traversal
Breadth-First Traversal, is a special case of Breadth-First Search that traverses the whole graph, instead of searching for a target node. The algorithm stays the same as we've defined it before, the difference being that we don't check for a target node and we don't need to find a path that leads to it.
This simplifies the implementation significantly - let's just print out each node being traversed to gain an intuition of how it passes through the nodes:
def traversal(adj_list, start_node):
visited = set()
queue = Queue()
queue.put(start_node)
visited.add(start_node)
while not queue.empty():
current_node = queue.get()
print(current_node, end = " ")
for next_node in adj_list[current_node]:
if next_node not in visited:
queue.put(next_node)
visited.add(next_node)
Now, let's define a simple graph:
graph = {
1 : [2, 3],
2 : [1, 3, 5],
3 : [1, 2, 4],
4 : [3],
5 : [2]
}
traversal(graph, 1)
Finally, let's run the code:
1 2 3 5 4
Step by step
Let's dive into this example a bit deeper and see how the algorithm works step by step. Here's a picture of the graph so we can easily follow the steps:

As we start the traversal from the start node 1, it is put into the visited set and into the queue as well. While we still have nodes in the queue, we extract the first one, print it, and check all of it's neighbours.
When going through the neigbours, we check if each of them is visited, and if not we add them to the queue and mark them as visited:
| Steps | Queue | Visited |
| Add start node `1` | [`1`] | {`1`} |
| Visit `1`, add `2` & `3` to Queue | [`2`, `3`] | {`1`} |
| Visit `2`, add `5 `to Queue | [`3`, `5`] | {`1`, `2`} |
| Visit `3`, add `4` to Queue | [`5`, `4`] | {`1`, `2,` `3`} |
| Visit `5`, no unvisited neighbours | [`4`] | {`1`, `2,` `3`, `5`} |
| Visit `4`, no unvisited neighbours | [ ] | {`1`, `2,` `3`, `5`, `4`} |
Time complexity
During Breadth-First Traversal, every node is visited exactly once, and every branch is also viewed once in case of a directed graph, that is, twice if the graph is undirected. Therefore, the time complexity of the BFS algorithm is O(|V| + |E|), where V is a set of the graph's nodes, and E is a set consisting of all of it's branches (edges).
Conclusion
In this guide, we've explained the theory behind the Breadth-First Search algorithm and defined it's steps.
We've depicted the Python implementation of both Breadth-First Search and Breadth-First Traversal, and tested them on example graphs to see how they work step by step. Finally, we've explained the time complexity of this algorithm.
from Planet Python
via read more
Saturday, November 27, 2021
Podcast.__init__: Making Orbital Mechanics More Accessible With Poliastro
Outer space holds a deep fascination for people of all ages, and the key principle in its exploration both near and far is orbital mechanics. Poliastro is a pure Python package for exploring and simulating orbit calculations. In this episode Juan Luis Cano Rodriguez shares the story behind the project, how you can use it to learn more about space travel, and some of the interesting projects that have used it for planning planetary and interplanetary missions.

from Planet Python
via read more
Summary
Outer space holds a deep fascination for people of all ages, and the key principle in its exploration both near and far is orbital mechanics. Poliastro is a pure Python package for exploring and simulating orbit calculations. In this episode Juan Luis Cano Rodriguez shares the story behind the project, how you can use it to learn more about space travel, and some of the interesting projects that have used it for planning planetary and interplanetary missions.
Announcements
- Hello and welcome to Podcast.__init__, the podcast about Python’s role in data and science.
- When you’re ready to launch your next app or want to try a project you hear about on the show, you’ll need somewhere to deploy it, so take a look at our friends over at Linode. With the launch of their managed Kubernetes platform it’s easy to get started with the next generation of deployment and scaling, powered by the battle tested Linode platform, including simple pricing, node balancers, 40Gbit networking, dedicated CPU and GPU instances, and worldwide data centers. Go to pythonpodcast.com/linode and get a $100 credit to try out a Kubernetes cluster of your own. And don’t forget to thank them for their continued support of this show!
- Your host as usual is Tobias Macey and today I’m interviewing Juan Luis Cano Rodriguez about Poliastro, an open source library for interactive Astrodynamics and Orbital Mechanics, with a focus on ease of use, speed, and quick visualization.
Interview
- Introductions
- How did you get introduced to Python?
- Can you describe what Poliastro is and the story behind it?
- What are some of the simulations that Poliastro is designed to be used for?
- How much knowledge of orbital mechanics is necessary to get started with Poliastro?
- Can you describe how the project is implemented?
- How have the goals and design of the project changed or evolved since you first started it?
- What are some of the design philosophies that you focus on to make the package accessible to the range of users that you support?
- Can you talk through the workflow of using Poliastro to do something like track the path of the ISS and its traversal of the debris field from the recent satellite destruction?
- What are some of the other libraries or frameworks that are commonly used with Poliastro?
- How are you using Poliastro in your own work?
- What are some overlooked or underused aspects of the project that you would like to highlight?
- What are the most interesting, innovative, or unexpected ways that you have seen Poliastro used?
- What are the most interesting, unexpected, or challenging lessons that you have learned while working on Poliastro?
- When is Poliastro the wrong choice?
- What do you have planned for the future of Poliastro?
Keep In Touch
Picks
Closing Announcements
- Thank you for listening! Don’t forget to check out our other show, the Data Engineering Podcast for the latest on modern data management.
- Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.
- If you’ve learned something or tried out a project from the show then tell us about it! Email hosts@podcastinit.com) with your story.
- To help other people find the show please leave a review on iTunes and tell your friends and co-workers
Links
- Poliastro
- Fortran 90 (if only this community existed back then! https://ift.tt/3oZQOwY
- Satellogic
- Read the Docs
- Wolfram Alpha
- Mathematica
- SageMath
- 2-Body Problem
- AstroPy
- Numba
- Import Linter
- Vallado "Fundamentals of Astrodynamics"
- International Space Station
- Starlink Satellites
- Planetary Ephemeritas Data
- Satellite Data
- Kerbal Space Program
- NumFOCUS
- Open Collective
- Python SGP4
- Libre Space Foundation
The intro and outro music is from Requiem for a Fish The Freak Fandango Orchestra / CC BY-SA
from Planet Python
via read more
Weekly Python StackOverflow Report: (ccciii) stackoverflow python report
These are the ten most rated questions at Stack Overflow last week.
Between brackets: [question score / answers count]
Build date: 2021-11-27 16:50:46 GMT
- Does NumPy array really take less memory than python list? - [8/2]
- array_2 = array_1 vs. array_2 = array_1.view() - [7/1]
- How can I use value_counts() only for certain values? - [5/3]
- Find the indices where a sorted list of integer changes - [5/3]
- pytube: AttributeError: 'NoneType' object has no attribute 'span' - [5/2]
- Using pandas nullable integer dtype in np.where condition - [5/2]
- Sum dataframe values in for loop inside a for loop - [5/1]
- Python 3.10 pattern matching (PEP 634) - wildcard in string - [5/1]
- How do I assign values from a dataframe to deciles created in another dataframe? - [5/0]
- Why do these Python import scenarios work (or not) the way they do? - [5/0]
from Planet Python
via read more
Subscribe to:
Posts (Atom)
-
Podcasts are a great way to immerse yourself in an industry, especially when it comes to data science. The field moves extremely quickly, an...
-
Dialogs are useful GUI components that allow you to communicate with the user (hence the name dialog ). They are commonly used for file Ope...
-
 This tutorial outlines object oriented programming (OOP) in Python with examples. It is a step by step guide which was designed for people w...
This tutorial outlines object oriented programming (OOP) in Python with examples. It is a step by step guide which was designed for people w...

