In this tutorial, we'll learn to build a Python 3 GUI app from scratch using wxPython and Urllib. We'll be consuming a third-party news REST API available from newsapi.org which provides breaking news headlines, and allows you to search for articles from over 30,000 news sources and blogs worldwide. We'll use Urllib for sending HTTP requests to the REST API and the json module to parse the response.
Throughout you'll understand how to create desktop user interfaces in Python 3, including adding widgets, and managing data. In more details, you'll see:
- How to use Urllib to send HTTP requests to fetch JSON data from a third-party REST API.
- How to use the
jsonmodule to parse JSON data into Python 3 dictionaries. - How to use the
webbrowsermodule to open URLs in your default web browser.
First of all, head over to the registration page and create a new account then take note of the provided API key which will be using later to access the news data.
What is wxPython
wxPython is a Python wrapper around wxWidgets - the cross platform C++ library for building desktop apps for macOS, Linux and Windows. wxPython was created by Robin Dunn.
Prerequisites
You will need to have the following prerequisistes:
- Python 3 and pip installed on your system,
- A basic knowledge of Python.
Installing wxPython 4
Let's start by installing wxPython 4 using pip. Open a new terminal and simply run the following command:
$ pip install wxpython
If the installation fails, you may be requiring some dependencies depending on your operating system. Check out the prerequisites section in the official GitHub repository for more information.
Creating your First wxPython 4 GUI Window
After installing wxPython, you can easily create your first GUI window by creating a Python single file and call the wx.App() and the wx.Frame() methods.
Inside your working folder, create a newsy.py file and add the following code:
import wx
app = wx.App()
frame = wx.Frame(parent=None, title='Newsy: Read the World News!')
frame.Show()
app.MainLoop()
In this example, we use two essentials classes - wx.App and wx.Frame.
The wx.App class is used to instantiate a wxPython application object .
From the wx.Appobject, you can call the MainLoop() method which starts the event loop which is used to listen for events in your application.
wx.Frame is used to create a window. In our example, we created a window with no parent has the Newsy: Read the World News! title.
Now, run your GUI app using the following command from your terminal:
$ python newsy.py
This is a screenshot of our GUI window:

Let's refactor our code and create a menu and status bars. First, we create a MainWindow class that extends the wx.Frame class:
class MainWindow(wx.Frame):
def __init__(self, parent, title):
super(MainWindow, self).__init__(parent, title = title, size = (600,500))
self.Centre()
self.CreateStatusBar()
self.createMenu()
def createMenu(self):
menu= wx.Menu()
menuExit = menu.Append(wx.ID_EXIT, "E&xit", "Quit application")
menuBar = wx.MenuBar()
menuBar.Append(menu,"&File")
self.SetMenuBar(menuBar)
self.Bind(wx.EVT_MENU, self.OnExit, menuExit)
def OnExit(self, event):
self.Close(True) #Close the frame
In the __init__() method, we call the Centre() method of wx.Frame to center the window in the screen. Next, we call the CreateStatusBar() method to create a status bar. Finally, we define and call the createMenu() method which:
- Creates a menu using the
wx.Menu()method, - Appends a menu item to quit the application,
- Creates a menu bar and add the a File menu to it,
- Binds the
EVT_MENUto theOnExit()method which simply calls theClose()method to close the window.
Next, refacor the code for creating the app as follows:
if __name__ == '__main__':
app = wx.App()
window= MainWindow(None, "Newsy - read worldwide news!")
window.Show()
app.MainLoop()
After running the app, this is a screenshot of our window at this point:

Adding a wxPython Panel
According to the docs:
A panel is a window on which controls are placed. It is usually placed within a frame. Its main feature over its parent class wx.Window is code for handling child windows and
TABtraversal, which is implemented natively if possible (e.g. in wxGTK) or by wxWidgets itself otherwise.
Now, let's create a panel called NewsPanel that extends wxPanel:
class NewsPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
self.SetBackgroundColour("gray")
Next, let's instantiate the class in the MainWindow constructor for actually adding a panel to our window:
class MainWindow(wx.Frame):
def __init__(self, parent, title):
super(MainWindow, self).__init__(parent, title = title, size = (600,500))
self.Centre()
NewsPanel(self)
self.createStatusBar()
self.createMenu()
Adding wxPython Lists for News and Sources
According to the docs:
A list control presents lists in a number of formats: list view, report view, icon view and small icon view. In any case, elements are numbered from zero. For all these modes, the items are stored in the control and must be added to it using
wx.ListCtrl.InsertItemmethod.
After creating our panel, let's add two lists which will hold the sources and the news items:
class NewsPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
self.SetBackgroundColour("gray")
self.sources_list = wx.ListCtrl(
self,
style=wx.LC_REPORT | wx.BORDER_SUNKEN
)
self.sources_list.InsertColumn(0, "Source", width=200)
self.news_list = wx.ListCtrl(
self,
size = (-1 , - 1),
style=wx.LC_REPORT | wx.BORDER_SUNKEN
)
self.news_list.InsertColumn(0, 'Link')
self.news_list.InsertColumn(1, 'Title')
We use wx.ListCtrl to create a list in wxPython, next we call the InsertColumn() method for adding columns to our lists. For our first list, we only add one Source column. For the seconf lists we add two Link and Title columns.
Creating a Layout with Box Sizer
According to the docs:
Sizers ... have become the method of choice to define the layout of controls in dialogs in wxPython because of their ability to create visually appealing dialogs independent of the platform, taking into account the differences in size and style of the individual controls.
Next, let's place the two lists side by side using the BoxSizer layout. wxPython provides absoulte positioning and also adavanced layout algorithms such as:
- wx.BoxSizer
- wx.StaticBoxSizer
- wx.GridSizer
- wx.FlexGridSizer
- wx.GridBagSizer
wx.BoxSizer allows you to place several widgets into a row or a column.
box = wx.BoxSizer(wx.VERTICAL | wx.HORIZONTAL)
The orientation can be wx.VERTICAL or wx.HORIZONTAL.
You can add widgets into the wx.BoxSizer using the Add() method:
box.Add(wx.Window window, integer proportion=0, integer flag = 0, integer border = 0)
In the __init__() method of our news panel, add the following code:
sizer = wx.BoxSizer(wx.HORIZONTAL)
sizer.Add(self.sources_list, 0, wx.ALL | wx.EXPAND)
sizer.Add(self.news_list, 1, wx.ALL | wx.EXPAND)
self.SetSizer(sizer)
This is a screenshot of our window with two lists:

Let's now start by populating the source list. First import the following modules:
import urllib.request
import json
Next, define the API_KEY variable which will hold your API key that you received after creating an account with NewsAPI.org:
API_KEY = ''
Fetching JSON Data Using Urllib.request
Next, in NewsPanel, add a method for grabbing the news sources:
def getNewsSources(self):
with urllib.request.urlopen("https://newsapi.org/v2/sources?language=en&apiKey=" + API_KEY) as response:
response_text = response.read()
encoding = response.info().get_content_charset('utf-8')
JSON_object = json.loads(response_text.decode(encoding))
for el in JSON_object["sources"]:
print(el["description"] + ":")
print(el["id"] + ":")
print(el["url"] + "\n")
self.sources_list.InsertItem(0, el["name"])
Next, call the method in the constructor:
class NewsPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
# [...]
self.getNewsSources()
That's it! If you run the application again, you should see a list of news sources displayed:

Now, when we select a news source from the list at left, we want the news from this source to get displayed on the list at the right. We first, need to define a method to fetch the news data. In NewsPanel, add the following method:
def getNews(self, source):
with urllib.request.urlopen("https://newsapi.org/v2/top-headlines?sources="+ source + "&apiKey=" + API_KEY) as response:
response_text = response.read()
encoding = response.info().get_content_charset('utf-8')
JSON_object = json.loads(response_text.decode(encoding))
for el in JSON_object["articles"]:
index = 0
self.news_list.InsertItem(index, el["url"])
self.news_list.SetItem(index, 1, el["title"])
index += 1
Next, we need to call this method when a source is selected. Here comes the role of wxPython events.
Binding wxPython Events
In the __init__() constructor of NewsPanel, call the Bind() method on the sources_list object to bind the wx.EVT_LIST_ITEM_SELECTED event of the list to the OnSourceSelected() method: ```py class NewsPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
# [...]
self.sources_list.Bind(wx.EVT_LIST_ITEM_SELECTED, self.OnSourceSelected)
Next, define the `OnSourceSelected()` method as follows:
```py
def OnSourceSelected(self, event):
source = event.GetText().replace(" ", "-")
self.getNews(source)
Now, run your application and select a news source, you should get a list of news from the select source in the right list:

Open External URLs in Web Browsers
Now, we want to be able to open the news article, when selected, in the web browser to read the full article. First import the webbrowser module:
import webbrowser
Next, in NewsPanel define the OnLinkSelected() method as follows:
def OnLinkSelected(self, event):
webbrowser.open(event.GetText())
Finally, bind the method to the wx.EVT_LIST_ITEM_SELECTED on the news_list object:
class NewsPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
# [...]
self.news_list.Bind(wx.EVT_LIST_ITEM_SELECTED , self.OnLinkSelected)
Now, when you select a news item, its corresponding URL will be opened in your default web browser so you can read the full article.
Resizing the Lists when the Window is Resized
If your resize your window, you'll notice that the lists are not resized accordingly. You can change this behavior by adding the following method to NewsPanel and bind it to the wx.EVT_PAINT event:
def OnPaint(self, evt):
width, height = self.news_list.GetSize()
for i in range(2):
self.news_list.SetColumnWidth(i, width/2)
evt.Skip()
Next, bind the method as follows:
class NewsPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
# [...]
self.Bind(wx.EVT_PAINT, self.OnPaint)

This is the full code:
Conclusion
In this tutorial, we've seen how to do desktop GUI development with Python 3 and wxPython. We've also seen:
- How to use Urllib to send HTTP requests to fetch JSON data from a third-party REST API.
- How to use the json module to parse JSON data into Python 3 dictionaries.
- How to use the
webbrowsermodule to open URLs in your default web browser.
We've also learned how to use wxPython to create windows, panels and lists and how to listen for events.
from Planet Python
via read more





 list of tuples consist of time vs traffic volume
list of tuples consist of time vs traffic volume
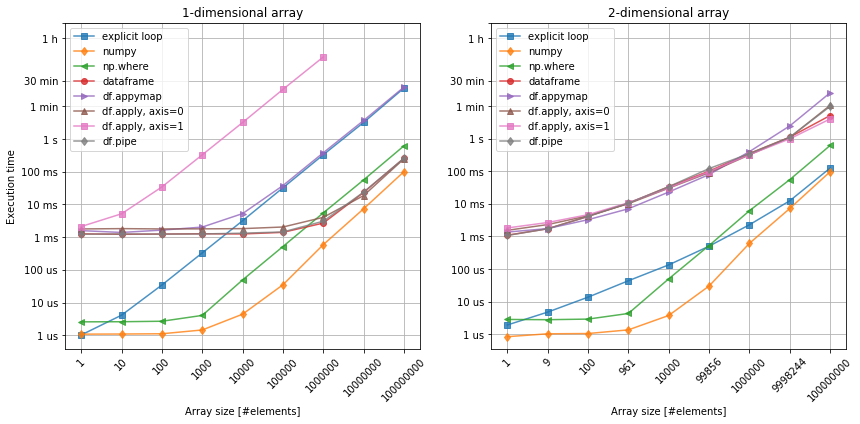 Figure 1. Selecting a data subset. Left: 1-dimensional array. Right: 2-dimensional array.
Figure 1. Selecting a data subset. Left: 1-dimensional array. Right: 2-dimensional array.
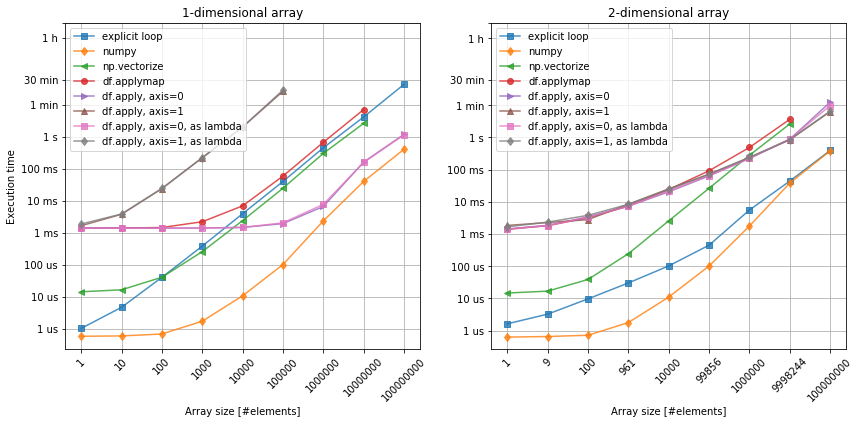 Figure 2. Applying a function to the data. Left: 1-dimensional array. Right: 2-dimensional array.
Figure 2. Applying a function to the data. Left: 1-dimensional array. Right: 2-dimensional array.
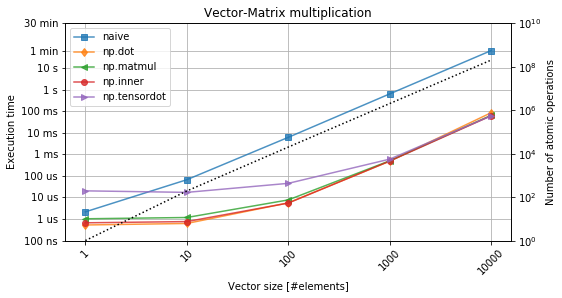 Figure 3. Vector-matrix multiplication. The black-dotted line denotes the number of operations.
Figure 3. Vector-matrix multiplication. The black-dotted line denotes the number of operations.



