There are many ways to share a static Jupyter notebook with others, such as posting it on GitHub or sharing an nbviewer link. However, the recipient can only interact with the notebook file if they already have the Jupyter Notebook environment installed.
But what if you want to share a fully interactive Jupyter notebook that doesn't require any installation? Or, you want to create your own Jupyter notebooks without installing anything on your local machine?
In this post, I'm going to review six services you can use to easily run your Jupyter notebook in the cloud. All of them have the following characteristics:
- They don't require you to install anything on your local machine.
- They are completely free (or they have a free plan).
- They give you access to the Jupyter Notebook environment (or a Jupyter-like environment).
- They allow you to import and export notebooks using the standard .ipynb file format.
- They support the Python language (and most support other languages as well).
Since all of these are cloud-based services, none of them will work for you if you are restricted to working with your data on-premise.
Table of Contents
Note: If you just want a quick summary, check out the comparison table.
Criteria for comparison
Here are the criteria on which I compared each of the six services:
Supported languages: Does this service support any programming languages other than Python?
Ability to install packages: Does this service allow you to install additional packages (or a particular version of a package), beyond the ones that are already installed?
Interface similarity: If the service provides a "Jupyter-like" interface (rather than the native Jupyter interface), how similar is its interface to Jupyter? (This makes it easier for existing Jupyter users to transition to this service.)
Keyboard shortcuts: Does this service use the same keyboard shortcuts as the Jupyter Notebook?
Missing features: Is there anything that the Jupyter Notebook can do that this service does not support?
Added features: Is there anything this service can do that the Jupyter Notebook does not support?
Ease of working with datasets: How easy does this service make it to work with your own datasets?
Internet access: Does this service give you Internet access from within the Notebook, so that you can read data from URLs when necessary?
Ability to work privately: Does this service allow you to keep your work private?
Ability to share publicly: Does this service provide a way for you to share your work publicly?
Ability to collaborate: Does this service allow you to invite someone to collaborate on a notebook, and can the collaboration occur in real-time?
Performance of the free plan: What computational resources (RAM and CPU) does this service provide? Does it give you access to a GPU (which is useful for deep learning)? How much disk space is included? How long can a session run?
Ability to upgrade for better performance: Can you pay for this service in order to access more computational resources?
Documentation and technical support: Is the service well-documented? Can you get in touch with someone if you run into a problem?
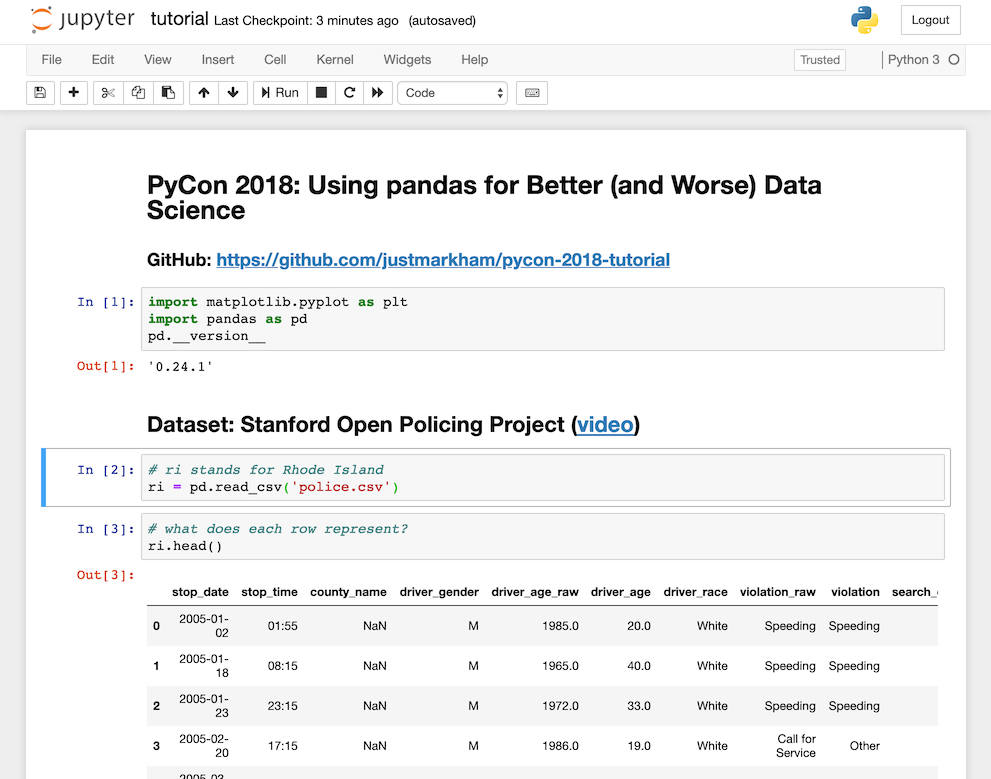
1. Binder
Binder is a service provided by the Binder Project, which is a member of the Project Jupyter open source ecosystem. It allows you to input the URL of any public Git repository, and it will open that repository within the native Jupyter Notebook interface. You can run any notebooks in the repository, though any changes you make will not be saved back to the repository. You don't have to create an account with Binder and you don't need to be the owner of the repository, though the repository must include a configuration file that specifies its package requirements.
Supported languages: Python (2 and 3), R, Julia, and any other languages supported by Jupyter.
Ability to install packages: You can specify your exact package requirements using a configuration file (such as environment.yml or requirements.txt).
Interface similarity: Binder uses the native Jupyter Notebook interface.
Keyboard shortcuts: Binder uses all of the same keyboard shortcuts as Jupyter.
Missing features: None.
Added features: None.
Ease of working with datasets: If your dataset is in the same Git repository, then it will automatically be available within Binder. If your dataset is not in that repository but is available at any public URL, then you can add a special file to the repository telling Binder to download your dataset. However, Binder does not support accessing private datasets.
Internet access: Yes.
Ability to work privately: No, since it only works with public Git repositories.
Ability to share publicly: Yes. You can share a URL that goes directly to your Binder, or someone can run your notebooks using the Binder website (as long as they know the URL of your Git repository).
Ability to collaborate: No. If you want to work with someone on the same notebook and your repository is hosted on GitHub, then you can instead use the normal pull request workflow.
Performance of the free plan: You will have access to up to 2 GB of RAM. There is no specific limit to the amount of disk space, though they ask you not to include "very large files" (more than a few hundred megabytes). Binder can be slow to launch, especially when it's run on a newly updated repository. Sessions will shut down after 20 minutes of inactivity, though they can run for 12 hours or longer. Binder has other usage guidelines, including a limit of 100 simultaneous users for any given repository.
Ability to upgrade for better performance: No. However, you do have the option of setting up your own BinderHub deployment, which can provide the same functionality as Binder while allowing you to customize the environment (such as increasing the computational resources or allowing private files).
Documentation and technical support: Binder has extensive documentation. Community support is available via Gitter chat and a Discourse forum, and product issues are tracked on GitHub.
Conclusion: If your notebooks are already stored in a public GitHub repository, Binder is the easiest way to enable others to interact with them. Users don't have to create an account, and they'll feel right at home if they already know how to use the Jupyter Notebook. However, you'll want to keep the performance limitations and user limits in mind!
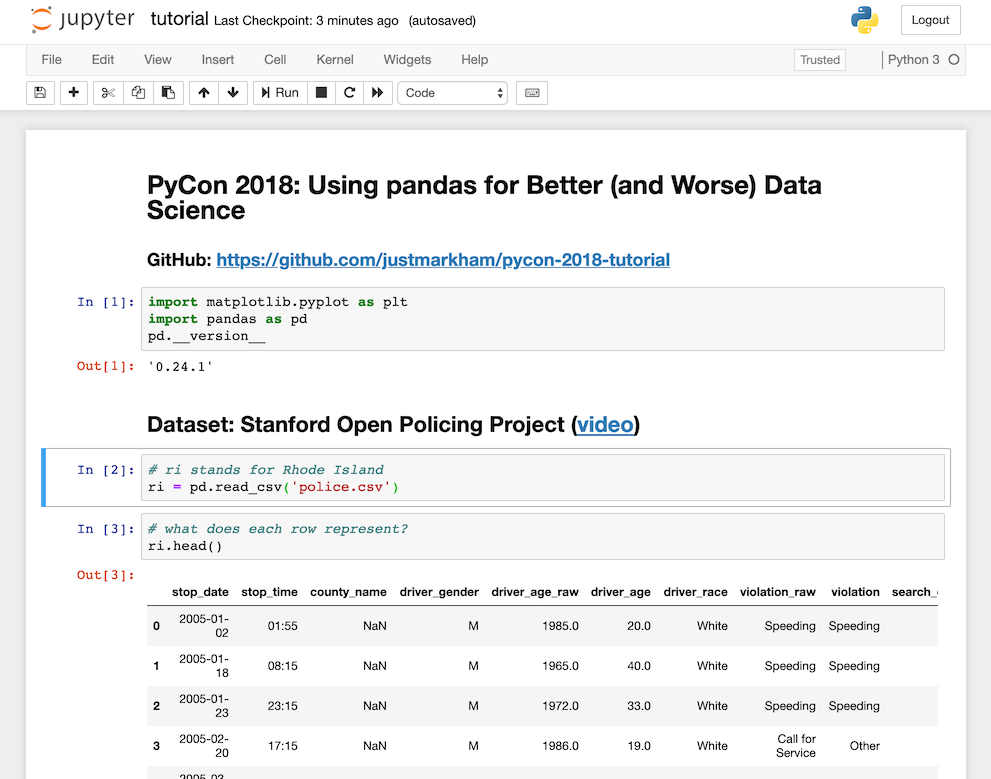
2. Kaggle Kernels
Kaggle is best known as a platform for data science competitions. However, they also provide a free service called Kernels that can be used independently of their competitions. After creating a Kaggle account (or logging in with Google or Facebook), you can create a Kernel that uses either a notebook or scripting interface, though I'm focusing on the notebook interface below.
Supported languages: Python (3 only) and R.
Ability to install packages: Hundreds of packages come pre-installed, and you can install additional packages using pip or by specifying the GitHub repository of a package. However, any additional packages you install will need to be reinstalled at the start of every session. Alternatively, you can ask Kaggle to include additional packages in their default installation.
Interface similarity: Visually, the Kernels interface looks quite different from the Jupyter interface. There's no menu bar or toolbar at the top of the screen, there's a collapsible sidebar on the right for adjusting settings, and there's a console docked below the notebook. However, working in the Kernels notebook actually feels very similar to working in the Jupyter Notebook, especially if you're comfortable with Jupyter's keyboard shortcuts. Also, note that a redesigned interface (shown in the screenshot above) will soon be released, which is more similar to the Jupyter interface and includes a simple menu bar.
Keyboard shortcuts: Kernels uses all of the same keyboard shortcuts as Jupyter.
Missing features:
- Because Kernels doesn't (yet) include a menu bar or a toolbar, many actions can only be done using keyboard shortcuts or the command palette.
- You can't download your notebook into other useful formats such as a Python script, HTML webpage, or Markdown file.
Added features:
- Kernels includes a lightweight version control system. Every time you want to save your work, there's a "commit" button which runs the entire notebook from top to bottom and adds a new version to the history. (You can keep working while this process takes place, which is essential for long-running notebooks.) Although you can't name the versions, you can display the "diff" between any two versions.
- Kernels allows you to selectively hide the input and/or output of any code cell, which makes it easy to customize the presentation of your notebook.
Ease of working with datasets: You can upload a dataset to Kaggle from your local computer, a URL, or a GitHub repository, and it will be hosted for free by another Kaggle service called Datasets. You can make the dataset private or public. Any dataset you upload, as well as any public dataset uploaded by a Kaggle user, can be accessed by any of your Kernels. The maximum size of each dataset is 20 GB, and a single Kernel can access multiple datasets.
Internet access: Yes.
Ability to work privately: Yes.
Ability to share publicly: Yes. If you choose to make your Kernel public, anyone can access it without creating a Kaggle account, and anyone with a Kaggle account can comment on your Kernel or copy it to their own account. Additionally, Kaggle also provides you with a public profile page, which displays all of your public Kernels and datasets.
Ability to collaborate: Yes. You can keep your Kernel private but invite specific Kaggle users to view or edit it. There's no real-time collaboration: It's more like working on separate copies of the Kernel, except that all commits are added to the same version history.
Performance of the free plan: You can access either a 4-core CPU with 17 GB of RAM, or a 2-core CPU with 14 GB of RAM plus a GPU. You will have 5 GB of "saved" disk space and 17 GB of "temporary" disk space, though any disk space used by your dataset does not count towards these figures. Sessions will shut down after 60 minutes of inactivity, though they can run for up to 9 hours.
Ability to upgrade for better performance: No.
Documentation and technical support: Kernels has adequate documentation. Support is available via a contact form and a forum.
Conclusion: As long as you're comfortable with a slightly cluttered interface (which has already been improved in the redesign), you'll have access to a high-performance environment in which it's easy to work with your datasets and share your work publicly (or keep it private). The included version control and collaboration features are also nice additions, though neither are fully-featured.
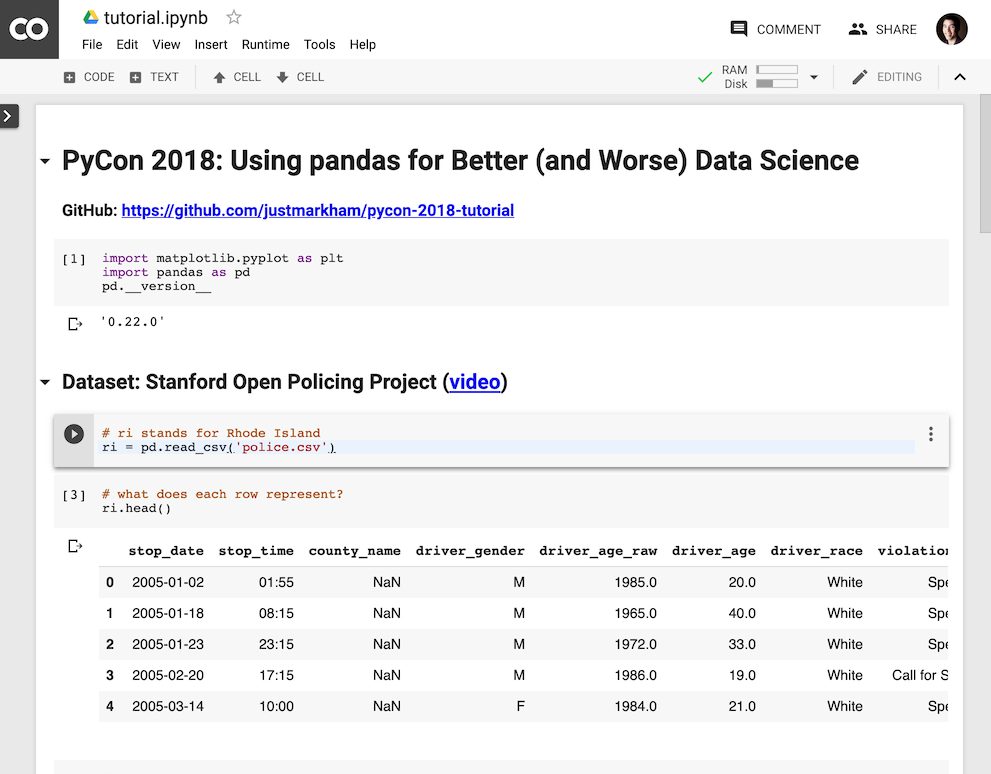
3. Google Colaboratory (Colab)
Google Colaboratory, usually referred to as "Google Colab," is available to anyone with a Google account. As long as you are signed into Google, you can quickly get started by creating an empty notebook, uploading an existing notebook, or importing a notebook from any public GitHub repository. Your Colab notebooks are automatically saved in a special folder in your Google Drive, and you can even create new notebooks directly from Drive.
Supported languages: Python (2 and 3) and Swift (which was added in January 2019). Kernels can also be installed for other languages, though the installation process varies by language and is not well-documented.
Ability to install packages: Hundreds of packages come pre-installed, and you can install additional packages using pip. However, any additional packages you install will need to be reinstalled at the start of every session.
Interface similarity: Visually, the Colab interface looks quite similar to the Jupyter interface. However, working in Colab actually feels very dissimilar to working in the Jupyter Notebook:
- Most of the menu items are different.
- Colab has changed some of the standard terminology ("runtime" instead of "kernel", "text cell" instead of "markdown cell", etc.)
- Colab has invented new concepts that you have to understand, such as "playground mode."
- Command mode and Edit mode in Colab work differently than they do in Jupyter.
Keyboard shortcuts: In Colab, most of the single letter keyboard shortcuts used by Jupyter (such as "a" to "insert cell above") have been changed to a multi-step process ("Ctrl+m" followed by "a"), though Colab does allow you to customize the shortcuts.
Missing features:
- Because the Colab menu bar is missing some items and the toolbar is kept very simple, some actions can only be done using keyboard shortcuts.
- You can't download your notebook into other useful formats such as an HTML webpage or Markdown file (though you can download it as a Python script).
Added features:
- Colab includes a lightweight version control system. It frequently saves the current state of your notebook, and you can browse through the revision history. However, you can't display the "diff" between versions, which means that you would have to do any comparisons manually.
- Colab allows you to add form fields to your notebook, which enables you to parameterize your code in an interactive way. However, these fields only work within Colab.
- When you create a section heading in your notebook, Colab makes every section collapsible and automatically creates a "table of contents" in the sidebar, which makes large notebooks easier to navigate.
Ease of working with datasets: You can upload a dataset to use within a Colab notebook, but it will automatically be deleted once you end your session. Alternatively, you can allow Colab to read files from your Google Drive, though it's more complicated than it should be. Colab also includes connectors to other Google services, such as Google Sheets and Google Cloud Storage.
Internet access: Yes.
Ability to work privately: Yes.
Ability to share publicly: Yes. If you choose to make your notebook public and you share the link, anyone can access it without creating a Google account, and anyone with a Google account can copy it to their own account. Additionally, you can authorize Colab to save a copy of your notebook to GitHub or Gist and then share it from there.
Ability to collaborate: Yes. You can keep your notebook private but invite specific people to view or edit it (using Google's familiar sharing interface). You and your collaborator(s) can edit the notebook at the same time and see each other's changes, as well as add comments for each other (similar to Google Docs), though there's a 30-second lag between when you make changes and when collaborators will see them. Also, you are not actually sharing your environment with your collaborators (meaning there is no syncing of what code has been run), which significantly limits the usefulness of near real-time collaboration.
Performance of the free plan: Colab does give you access to a GPU or a TPU. Otherwise, Google does not provide any specifications for their environments. If you connect Colab to Google Drive, that will give you up to 15 GB of disk space for storing your datasets. Sessions will shut down after 60 minutes of inactivity, though they can run for up to 12 hours.
Ability to upgrade for better performance: No. However, you do have the option of connecting to a local runtime, which allows you to execute code on your local hardware and access your local file system.
Documentation and technical support: Colab has minimal documentation, which is contained within an FAQ page and a variety of sample notebooks. Support is available via GitHub issues, and community support is available via Stack Overflow.
Conclusion: The greatest strength of Colab is that it's easy to get started, since most people already have a Google account, and it's easy to share notebooks, since the sharing functionality works the same as Google Docs. However, the cumbersome keyboard shortcuts and the difficulty of working with datasets are significant drawbacks. The ability to collaborate on the same notebook is useful, but less useful than it could be since you're not sharing an environment.
4. Microsoft Azure Notebooks
To get started with Azure Notebooks, you first sign in with a Microsoft or Outlook account (or create one). The next step is to create a "project", which is structured identically to a GitHub repository: it can contain one or more notebooks, Markdown files, datasets, and any other file you want to create or upload, and all of these can be organized into folders. Also like GitHub, you can initialize a project with a README file, which will automatically be displayed on the project page. If your work is already stored on GitHub, you can import the entire repository directly into a project.
Supported languages: Python (2 and 3), R, and F#.
Ability to install packages: Hundreds of packages come pre-installed, you can install additional packages using pip or conda, and you can specify your exact package requirements using a configuration file (such as environment.yml or requirements.txt).
Interface similarity: Azure uses the native Jupyter Notebook interface.
Keyboard shortcuts: Azure uses all of the same keyboard shortcuts as Jupyter.
Missing features: None.
Added features:
- The RISE extension comes pre-installed, which allows you to instantly present your notebook as a live reveal.js-based slideshow.
- The jupyter_contrib_nbextensions package comes pre-installed, which gives you easy access to a collection of 50+ Jupyter Notebook extensions for enhancing the notebook interface.
Ease of working with datasets: You can upload a dataset to your project from your local computer or a URL, and it can be accessed by any notebook within your project. Azure also includes connectors to other Azure services, such as Azure Storage and various Azure databases.
Internet access: Yes.
Ability to work privately: Yes.
Ability to share publicly: Yes. If you choose to make your project public, anyone can access it without creating a Microsoft account, and anyone with a Microsoft account can copy it to their own account. Additionally, Azure also provides you with a public profile page (very similar to a GitHub profile), which displays all of your public projects.
Ability to collaborate: No, though this is a planned feature.
Performance of the free plan: You will have access to 4 GB of RAM and 1 GB of disk space (per project). Sessions will shut down after 60 minutes of inactivity, though they can run for 8 hours or longer.
Ability to upgrade for better performance: Yes. You can pay for an Azure subscription, though the setup process is non-trivial and the pricing is complicated.
Documentation and technical support: Azure has extensive documentation. Support is available via GitHub issues.
Conclusion: The greatest strength of Azure Notebooks is its ease of use: the project structure (borrowed from GitHub) makes it simple to work with multiple notebooks and datasets, and the use of the native Jupyter interface means that existing Jupyter users will have an easy transition. However, the RAM and disk space are not particularly generous, and the lack of collaboration is a big gap in the functionality.
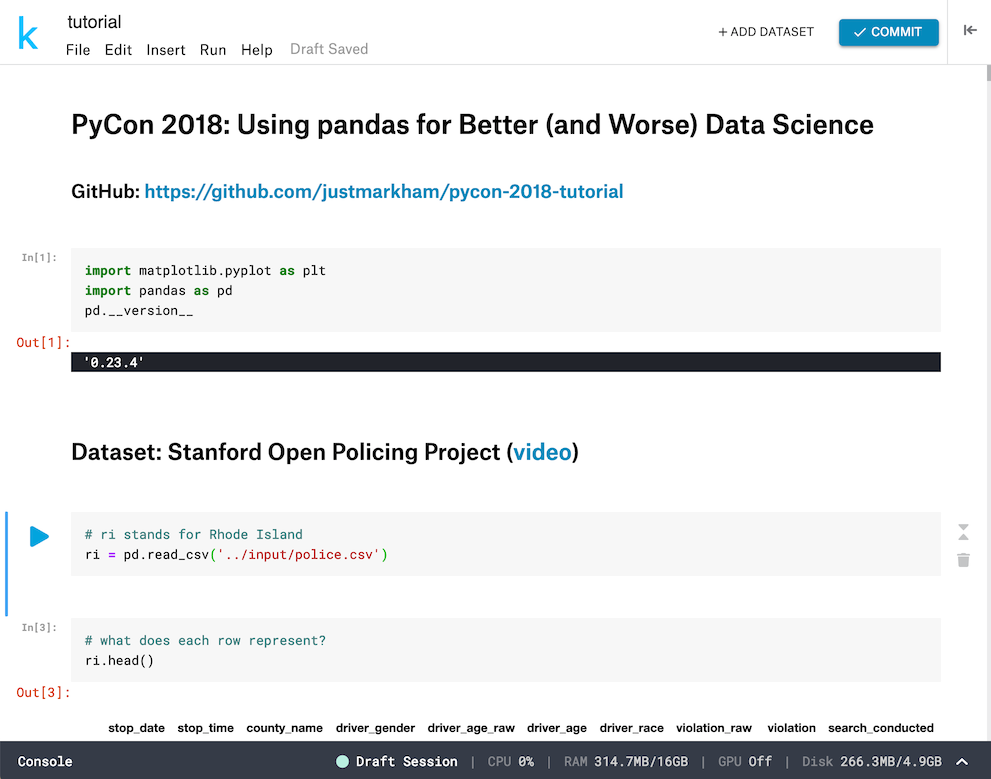
5. CoCalc
CoCalc, short for "collaborative calculation", is an online workspace for computation in Python, R, Julia, and many other languages. It allows you to create and edit Jupyter Notebooks, Sage worksheets, and LaTeX documents. After creating a CoCalc account, the first step is to create a "project", which can contain one or more notebooks, Markdown files, datasets, and any other file you want to create or upload, and all of these can be organized into folders. The project interface is a bit overwhelming at first, but it looks much more familiar once you create or open a notebook.
Supported languages: Python (2 and 3), R, Julia, and many other languages.
Ability to install packages: Hundreds of packages come pre-installed. You can install additional packages using pip, but this is not available when using a free plan. Alternatively, you can ask CoCalc to include additional packages in their default installation.
Interface similarity: Although CoCalc does not use the native Jupyter Notebook interface (they rewrote it using React.js), the interface is very similar to Jupyter, with only a few minor modifications. You can actually switch to using the native Jupyter Notebook from within CoCalc, though it's not recommended since you would lose access to the most valuable CoCalc features ("time travel" and real-time collaboration, which are discussed below).
Keyboard shortcuts: CoCalc uses almost all of the same keyboard shortcuts as Jupyter.
Missing features: CoCalc does not currently support interactive widgets.
Added features:
- CoCalc includes a powerful version control feature called time travel, which records all of your changes to the notebook in fine detail, and allows you to browse those changes using an intuitive slider control.
- CoCalc saves a backup of all of your project files every few minutes, which means you can recover older versions of your files if needed.
- CoCalc includes additional features for instructors, such as the ability to distribute and grade assignments, and the ability to watch students while they work and chat with them about the assignment.
Ease of working with datasets: You can upload a dataset to your project from your local computer, and it can be accessed by any notebook within your project.
Internet access: No, this is not available when using a free plan.
Ability to work privately: Yes.
Ability to share publicly: Yes. If you choose to make your notebook public and you share the link, anyone can access it without creating a CoCalc account, and anyone with a CoCalc account can copy it to their own account.
Ability to collaborate: Yes. You can keep your notebook private but invite specific people to edit it. You and your collaborator(s) can edit the notebook at the same time and see each other's changes (and cursors) in real-time, as well as chat (using text or video) in a window next to the notebook. The status and the results of all computations are also synchronized, which means that everyone involved will experience the notebook in the same way.
Performance of the free plan: You will have access to a 1-core shared CPU with 1 GB of shared RAM, and 3 GB of disk space (per project). Sessions will shut down after 30 minutes of inactivity, though they can run for up to 24 hours.
Ability to upgrade for better performance: Yes. You can pay for a CoCalc subscription, which starts at $14/month. Alternatively, you can install the CoCalc Docker image on your own computer, which allows you to run a private multi-user CoCalc server for free.
Documentation and technical support: CoCalc has extensive documentation. Support is available via email and a contact form, and product issues are tracked on GitHub.
Conclusion: The most compelling reasons to use CoCalc are the real-time collaboration and the "time travel" version control features, as well as the course management features (if you're an instructor). Although the interface is a bit cluttered, existing Jupyter users would have a relatively easy time transitioning to CoCalc. However, the free plan does have some important limitations (inability to install additional packages or access the Internet), and the performance of the free plan is modest.
6. Datalore
Datalore was created by JetBrains, the same company who makes PyCharm (a popular Python IDE). Getting started is as easy as creating an account, or logging in with a Google or JetBrains account. You can either create a new Datalore "workbook" or upload an existing Jupyter Notebook. Datalore workbooks are stored in a proprietary format, though it does support importing and exporting the standard .ipynb file format.
Supported languages: Python 3 only.
Ability to install packages: Hundreds of packages come pre-installed, and you can install additional packages using pip or conda, or by specifying the GitHub repository of a package.
Interface similarity: When you open Datalore, the interface does resemble a Jupyter Notebook in the sense that there are code and Markdown cells as well as output below those cells. However, there are some important differences between the Datalore and Jupyter interfaces:
- Cells (which Datalore calls "blocks") are not numbered, because the ordering of cells is enforced. In other words, all of your code must be written in the order in which you ultimately want it to run.
- The notebook (which Datalore calls a "workbook") can have multiple worksheets, similar to Google Sheets, which is a convenient way to break long workbooks into logical sections. If you create multiple worksheets in a workbook, all of the worksheets share the same environment. Because cell order is important in Datalore, the cells in the second worksheet are treated as coming after the cells in the first worksheet, the third worksheet comes after the second worksheet, and so on.
- There are many other interface differences, which are explained in the "added features" section.
Keyboard shortcuts: Keyboard shortcuts are available for most actions in Datalore, but the shortcuts are wildly different from those used by Jupyter.
Missing features:
- Datalore does not use the IPython kernel, and thus IPython magic functions and shell commands are not available. (However, optional access to the IPython kernel is a planned feature.)
- Because the Datalore menu bar is kept very simple and there's no toolbar, many actions can only be done using keyboard shortcuts.
- You can't download your workbook into other useful formats such as a Python script, HTML webpage, or Markdown file.
- Datalore does not support all of the commonly supported Markdown features in its Markdown cells. (However, improved Markdown support is a planned feature.)
- Datalore does not support interactive widgets.
- Datalore does not include multicursor support.
Added features:
- Cells are automatically run as you write them, which Datalore calls "live computation". This actually makes it easier to debug code as you write it, since you can see the results of your code immediately. (Live computation can be disabled, in which case you can manually trigger cells to run.)
- Because cells will always run in the order in which they are arranged, Datalore can track cell dependencies. This means that when a given cell is edited, Datalore will determine which cells below it are potentially affected and will immediately re-run those cells (assuming live computation is enabled). If the edit causes an error in a dependent cell, those errors will immediately be flagged.
- Datalore allows you to display cell inputs and outputs sequentially (like in Jupyter) or in "split view", in which case the inputs and outputs are in two separate panes. When using sequential view, Datalore also makes it easy to hide all inputs or hide all outputs.
- Datalore includes more "intelligence" than Jupyter in its code completion.
- As you write code, Datalore provides context-aware suggestions (called "intentions") for which actions you might want to take. For example, after typing the name of a DataFrame, the intentions might include "drop string columns", "histogram", and "train test split". When you click an intention, Datalore actually generates the code for you, which can be a useful way to learn the code behind certain tasks.
- Datalore includes a well-designed version control system. It frequently saves the current state of your workbook, and you can quickly browse the diffs between the current version and any past versions. You can also choose to add a message when saving the workbook, and then filter the list of versions to only include those versions with a message.
- Datalore gives you access to a plotting library called datalore.plot, which is very similar to R's ggplot2, though you can only use it inside of Datalore.
Ease of working with datasets: You can upload a dataset to your workbook from your local computer or a URL, but it can only be accessed by that particular workbook. This would be a significant annoyance if you work with the same dataset(s) across many workbooks. (However, sharing datasets between workbooks is a planned feature.)
Internet access: Yes.
Ability to work privately: Yes.
Ability to share publicly: No.
Ability to collaborate: Yes. You can keep your workbook private but invite specific people to view or edit it. You and your collaborator(s) can edit the notebook at the same time and see each other's changes (and cursors) in real-time. The status and the results of all computations are also synchronized, which means that everyone involved will experience the notebook in the same way.
Performance of the free plan: You will have access to a 2-core CPU with 4 GB of RAM, and 10 GB of disk space. Sessions will shut down after 60 minutes of inactivity, though there is no specific limit on the length of individual sessions. You can use the service for up to 120 hours per month.
Ability to upgrade for better performance: No, though there will soon be a paid plan which offers more disk space and a more powerful CPU (or GPU).
Documentation and technical support: Datalore has minimal documentation, which is contained within sample workbooks. Support is available via a Discourse forum.
Conclusion: Rather than being an adaptation of the Jupyter Notebook, Datalore is more like a reinvention of the Notebook. It includes an innovative feature set, including live computation, dependency tracking, real-time collaboration, and built-in version control. However, existing Jupyter users may have a challenging time transitioning to Datalore, especially since cell ordering is enforced and all of the keyboard shortcuts are quite different. As well, Datalore currently includes some notable limitations, namely that workbooks can't be shared publicly and uploaded datasets can't be shared between workbooks.
How to choose the right service for you
Out of the six options presented, there's not one clear "winner". Instead, the right choice for you will depend on your priorities. Below are my suggestions for what you should choose, based on your particular needs. (Note: You can also view this as a comparison table.)
You use a language other than Python: Binder and CoCalc support tons of languages. Azure supports Python, R and F#, Kernels supports Python and R, Colab supports Python and Swift, and Datalore only supports Python.
You need to use Python 2: Binder, Colab, Azure, and CoCalc all support Python 2 and 3, whereas Kernels and Datalore only support Python 3.
You work with non-standard packages: Binder and Azure allow you to specify your exact package requirements using a configuration file. CoCalc and Datalore allow you to install additional packages, which will persist across sessions, though this is not available with CoCalc's free plan. Kernels and Colab also allow you to install additional packages, though they do not persist across sessions. Kernels and CoCalc accept user requests for which packages should be included in their default installation.
You love the existing Jupyter Notebook interface: Binder and Azure use the native Jupyter Notebook interface, and CoCalc uses a nearly identical interface. Kernels is visually different from Jupyter but works like it, whereas Colab is visually similar to Jupyter but does not work like it. Datalore is the furthest from the existing Jupyter Notebook.
You are a heavy user of keyboard shortcuts: Binder, Kernels, and Azure use the same keyboard shortcuts as Jupyter, and CoCalc uses almost all of the same shortcuts. Datalore uses completely different keyboard shortcuts, and Colab uses cumbersome multi-step keyboard shortcuts (though they can be customized).
You prefer a point-and-click interface: Binder, Azure, and CoCalc allow you to perform all actions by pointing and clicking, whereas Kernels, Colab, and Datalore require you to use keyboard shortcuts for certain actions.
You want an integrated version control system: CoCalc and Datalore provide the best interfaces for version control. Kaggle's version control system is more limited, and Colab's system is even more limited. Binder and Azure do not provide a version control system.
You work with a lot of datasets: Kernels works seamlessly with Kaggle Datasets, a full-featured (and free) service for hosting datasets of up to 20 GB each. CoCalc offers 3 GB of disk space per project, and any dataset you upload can be accessed by any notebook in your project. Azure has similar functionality, except it offers 1 GB of disk space per project. Datalore offers 10 GB of total disk space, though every dataset you upload has to be linked to a particular workbook. Colab will discard any datasets you upload when your session ends, unless you link Colab to your Google Drive. Binder is best for small datasets that are either stored in your Git repository or located at a public URL.
Your project is already hosted on GitHub: Binder can run your notebooks directly from GitHub, Azure will allow you to import an entire GitHub repository, and Colab can import a single notebook from GitHub. Kernels, CoCalc, and Datalore don't provide any similar functionality.
You need to keep your work private: All of the options except for Binder support working in private.
You need to keep your data on-premise: None of these cloud-based services allow you to keep your data on-premise. However, you can set up Binder or CoCalc on your own server, since BinderHub and the CoCalc Docker image are both open source, which would allow you to keep your data on-premise.
You want to share your work publicly: Binder creates the least friction possible when sharing, since people can view and run your notebook without creating an account. Kernels, Colab, Azure, and CoCalc allow you to share a URL for read-only access, while requiring users to create an account if they want to run your notebook. Kernels and Azure make sharing even easier by providing you with a public profile page. Datalore does not allow for public sharing.
You need to collaborate with others: CoCalc and Datalore support real-time collaboration. Colab supports collaborating on the same document, though it's not quite real-time and you're not sharing the same environment. Kernels supports a form of collaboration in which you're sharing a version history. Binder and Azure don't include any collaboration functionality, though with Binder it could easily occur through the normal GitHub pull request workflow.
You want a high performance environment: Kernels provides the most powerful environment (4-core CPU and 17 GB RAM), followed by Datalore (2-core CPU and 4 GB RAM), Azure (4 GB RAM), Binder (up to 2 GB RAM), and CoCalc (1-core CPU and 1 GB RAM). Colab does not provide specifications for its environment.
You need access to a GPU: Kernels and Colab both provide free access to a GPU. GPU access is available to paying customers of Azure and (soon) Datalore. GPU access is not available through Binder or CoCalc.
You prefer to use a non-commercial tool: Binder is the only option that is managed by a non-commercial entity.
Similar services which were not reviewed
The following services are similar to the six options above, but were not included in my comparison:
- I didn't include any service that only provides access to JupyterLab, such as Notebooks AI, Kyso, and CyVerse. (Note that Binder, Azure, and CoCalc all allow you to use JupyterLab instead of Jupyter Notebook if you prefer.)
- I didn't include IBM Watson Studio Cloud because the process of getting started is cumbersome, the interface is overly complicated, the free plan has lots of limitations, and there were lots of error messages during my testing.
- I didn't include Gryd because the free plan requires an academic email address, and I didn't include Code Ocean because the free plan is severely limited without an academic email address.
- I didn't include ZEPL because it doesn't allow you to export notebooks using the standard .ipynb format.
- I didn't include any paid services, such as Saturn Cloud, Crestle.ai, Paperspace, and Salamander.
My fact-checking process
This article is the result of 50+ hours of research, testing, and writing. In addition, I shared drafts of this article with the relevant teams from Binder, Kaggle, Google, Microsoft, CoCalc, and Datalore in March 2019. I received detailed feedback from all six companies/organizations (thank you!), which I incorporated into the article before publishing.
That being said, these services are constantly changing, and it's likely that some of this information will become outdated in the future. If you believe that something in this article is no longer correct, please leave a comment below, and I'd be happy to consider updating the article.
P.S. Want to master the Jupyter Notebook? Subscribe to the Data School newsletter to find out when my new course launches!
from Planet Python
via
read more








{kind=link}